
I am now an Associate Professor with the Hong Kong University of Science and Technology (HKUST), leading the Creative, Controllable & Cognitive Computing Group (C4G) in HKUST. Previously, I worked as an Associate Professor at Sun Yat-sen University, and an applied research scientist at Tencent, solving real-world problems using computer vision and machine learning techniques. Prior to Tencent, I worked for Amazon in Palo Alto, California, where I developed deep models for better visual search experience. Before that, I worked as a research scientist in Tencent AI Lab. The techniques I have developed/involved have been shipped to several products in Tencent such as WeChat, QQ, Tencent Video, Tencent Yuanbao, Tencent Cloud, and myapp. I received the Ph.D. degree from Imperial College London, UK, 2016, under the supervision of Prof. Tae-Kyun Kim, and working closely with Dr. Bjorn Stenger, M.E. degree from Institute of Automation, Chinese Academy of Sciences, China, 2012, under the supervision of Prof. Weiming Hu, and B.E. degree from Huazhong University of Science and Technology, China, 2009.
I have published over 100 peer-reviewed papers in top-tier conferences and journals, like ICML, NeurIPS, CVPR, ICCV, ECCV, SIGGRAPH, ACL, ICLR, TPAMI, AI, IJCV. My work is selected into the CVPR 2019 Best Paper Finalist and I was awarded the 2022 ACM China Rising Star Award (Guangzhou Chapter). I have served as Senior Area Editor for IEEE Signal Processing Letters, Associate Editor for IEEE Transactions on Image Processing, Neurocomputing, IET Computer Vision, (Senior) Area Chair for ICLR, NeurIPS, ACM MM, ICML, IJCAI, BMVC, and Senior Program Committee member for AAAI and IJCAI, regular reviewer for top conferences and journals like TPAMI, IJCV, CVPR, ICML, ICCV. I have been elected among Top 2% Scientists worldwide (2023, 2024, 2025) by Stanford/Elsevier.
Vacancies: our group begin to review the application for 27 spring/fall PhD students. The openings are funding-dependent on a rolling basis. If you are interested, please email me your CV and research interests. Priority will be given to candidates with outstanding academic background and strong publication record, those who are competitive applicants for the Hong Kong PhD Fellowship Scheme (HKPFS), as well as individuals who are willing to work as a Research Assistant (RA) or intern prior to their PhD studies.
[Curriculum Vitae] [HKUST Profile]
Research
I conduct research on creative AI. Specifically, my current research focuses on several topics, such as image/video generation and restoration/enhancement. My research is supported by the following sponsors.
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()

![]()
![]()
![]()
Updates
- 2026/07: Our group secured funding from Kuaishou, Tencent Video, Baidu and Research Grants Council of Hong Kong (RGC).
- 2026/07: I will give a talk in 2026莲花山人工智能大会: 青年科学家论坛.
- 2026/06: Five papers are accepted by ECCV 2026.
- 2026/06: We are organizing a special issue “Generative Models for Computer Vision” in Pattern Recognition, see the CFP.
- 2026/05: A joint work with Sun Yat-sen University Cancer Center is accepted by Nature Communications.
- 2026/05: Received IEEE Signal Processing Society Outstanding Editorial Board Member Award for my service to IEEE Signal Processing Letters as Senior Area Editor.
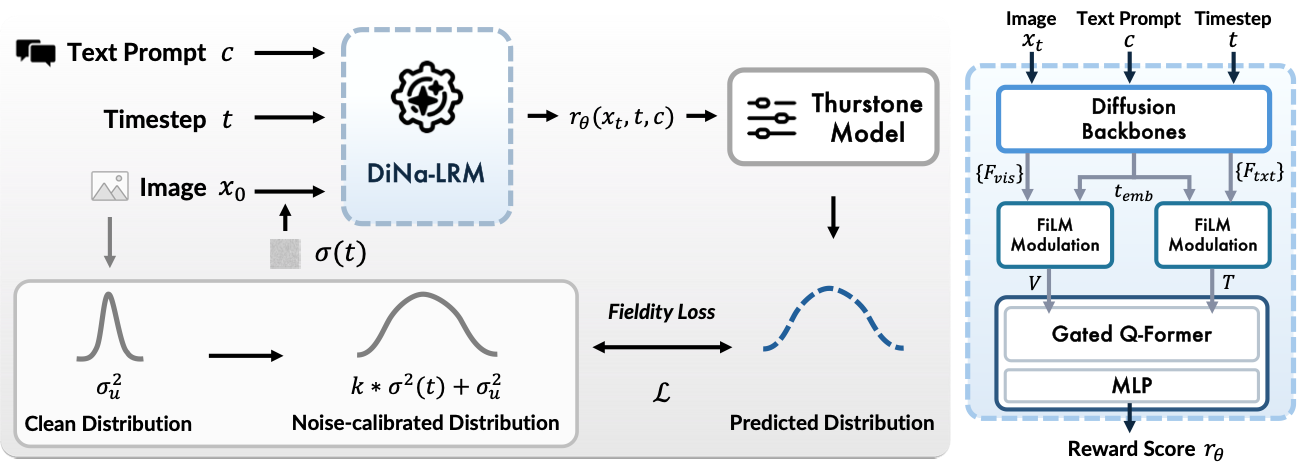
- 2026/05: DiNa-LRM is accepted by ICML 2026.
- 2026/03: I will give a talk in Chinese Congress on Image and Graphics 2026 (中国图像图形大会): 低质量视觉处理与质量评价论坛.
- 2026/03: I will serve as Senior Area Chair for NeurIPS 2026 and Area Chair for ACCV 2026.
- 2026/02: I will serve as Area Chair for ACM Multimedia 2026.
- 2026/02: Received an Outstanding Senior Program Committee Service Award (35 out of 1728 SPC) from AAAI 2026 Organization.
- 2026/02: Recent acceptance: 2 ICLR + 6 CVPR.
Recent Work [More]

|
Tianlin Pan*, Lianyu Pang*, Cheng Da, Huan Yang, Changqian Yu, Kun Gai, Wenhan Luo, arXiv:2606.27771. [arXiv] [Project Page] [Code] |

|
Nan Chen, Yiyang Cai, Rongchang Xie, Junwen Pan, Cheng Chen, Weinan Jia, Zhuowei Chen, Wen Zhou, Zhenbang Sun, Wenhan Luo, arXiv:2606.26058. [arXiv] [Project Page] [Code] 
|

|
Huaqiu Li, Jiahao Wang, Sijia Cai, Hualian Sheng, Bing Deng, Jieping Ye, Wenhan Luo, European Conference on Computer Vision (ECCV), 2026. [arXiv] [Project Page] [Code] [Hugging Face Model] 
|

|
Hanxiao Sun*, Mingxin Yang*, Shuhui Yang, Zebin He, Xintong Han, Hongbo Fu, Chunchao Guo, Wenhan Luo, European Conference on Computer Vision (ECCV), 2026. [arXiv] [Project Page] [Code] |

|
Lianyu Pang*, Tianlin Pan*, Cheng Da, Changqian Yu, Huan Yang, Kun Gai, Song Guo, Wenhan Luo, arXiv:2606.08788. [arXiv] [Project Page] [Code] |

|
Zebin He, Mingxin Yang, Shuhui Yang, Hanxiao Sun, Xintong Han, Chunchao Guo, Wenhan Luo, arXiv:2605.19727. [arXiv] [Project Page] [Code] |
|
Gongye Liu, Bo Yang, Yida Zhi, Zhizhou Zhong, Lei Ke, Didan Deng, Han Gao, Yongxiang Huang, Kaihao Zhang, Hongbo Fu, Wenhan Luo, International Conference on Machine Learning (ICML), 2026. [arXiv] [Code] 
|

|
Zixuan Ye, Quande Liu, Cong Wei, Yuanxing Zhang, Xintao Wang, Pengfei Wan, Kun Gai, Wenhan Luo, Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026. [arXiv] [Project Page] |
|
Zhizhou Zhong, Yicheng Ji, Zhe Kong, Yiying Liu, Jiarui Wang, Jiasun Feng, Lupeng Liu, Xiangyi Wang, Yanjia Li, Yuqing She, Ying Qin, Huan Li, Shuiyang Mao, Wei Liu, Wenhan Luo, arXiv:2511.23475. [arXiv] [Project Page] [Code] [Gradio] [Hugging Face Model] 
|
|

|
Zixuan Ye, Xuanhua He, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Qifeng Chen, Wenhan Luo, International Conference on Learning Representations (ICLR), 2026. [arXiv] [Project Page] |
|
Zhe Kong, Feng Gao, Yong Zhang, Zhuoliang Kang, Xiaoming Wei, Xunliang Cai, Guanying Chen, Wenhan Luo, Neural Information Processing Systems (NeurIPS), 2025. [arXiv] [Project Page] [Code] [Hugging Face Model] [Gradio] 
|
|

|
Yiyang Cai, Zhengkai Jiang, Yulong Liu, Chunyang Jiang, Wei Xue, Yike Guo, Wenhan Luo, Neural Information Processing Systems (NeurIPS), 2025. [PDF] [Project Page] [Code] 
|

|
Zebin He, Mingxin Yang, Shuhui Yang, Yixuan Tang, Tao Wang, Kaihao Zhang, Guanying Chen, Yuhong Liu, Jie Jiang, Chunchao Guo, Wenhan Luo, Proc. of International Conference on Computer Vision (ICCV), Hawaii, USA, 2025. (Highlight) [arXiv] [Project Page] [Code] 
|

|
Zhe Kong, Le Li, Yong Zhang, Feng Gao, Shaoshu Yang, Tao Wang, Kaihao Zhang, Zhuoliang Kang, Xiaoming Wei, Guanying Chen, Wenhan Luo, ACM SIGGRAPH, 2025. [PDF] [Project Page] [Code] 
|

|
Zixuan Ye, Huijuan Huang, Xintao Wang, Pengfei Wan, Di Zhang, Wenhan Luo, Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025. [arXiv] [Github] [Project Page] 
|

|
Jingyun Xue, Hongfa Wang, Qi Tian, Yue Ma, Andong Wang, Zhiyuan Zhao, Shaobo Min, Wenzhe Zhao, Kaihao Zhang, Heung-Yeung Shum, Wei Liu, Mengyang Liu, Wenhan Luo, International Conference on Learning Representations (ICLR), 2025. [PDF] [Project Page] [API in Tencent Cloud] |
Experience
I have studied/interned/worked in the following affiliations.
![]()








