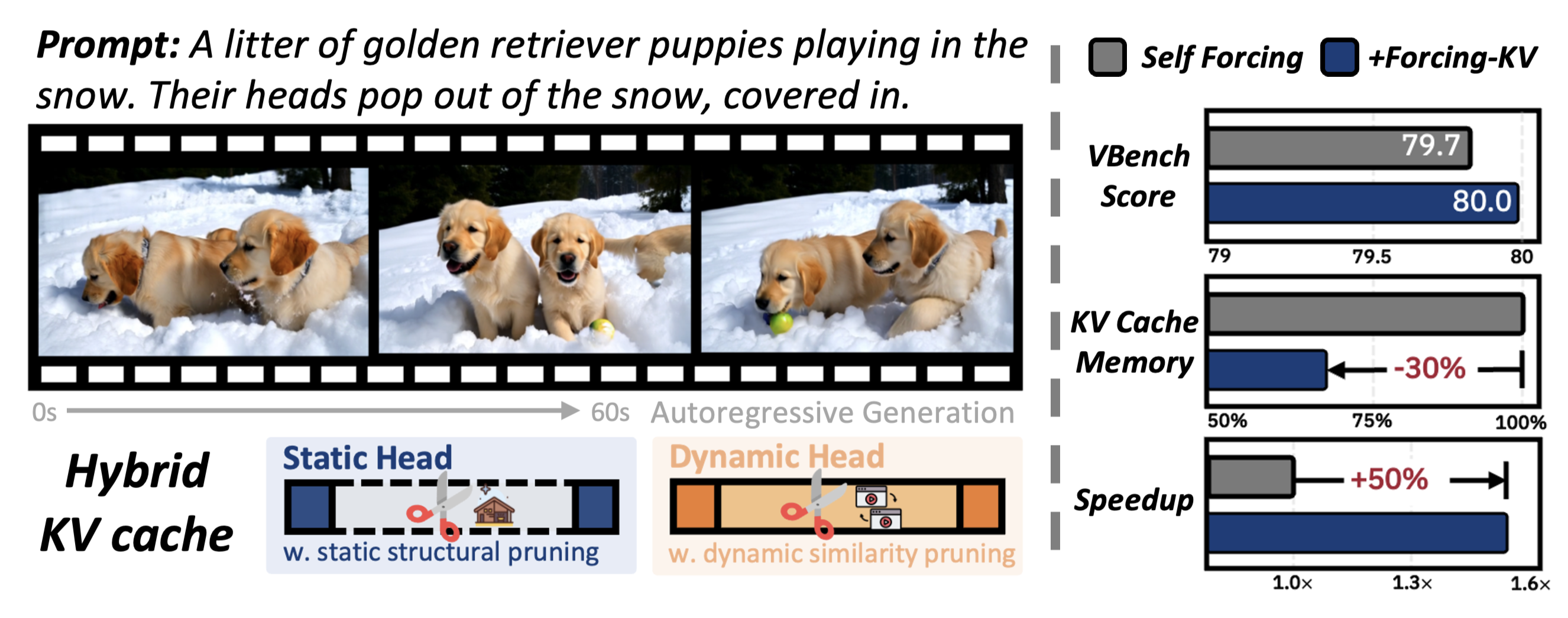
Huaqiu Li, Jiahao Wang, Sijia Cai, Hualian Sheng, Bing Deng, Jieping Ye, Wenhan Luo,
European Conference on Computer Vision (ECCV), 2026.
[arXiv] [Project Page] [Code] [Hugging Face Model]


Hanxiao Sun*, Mingxin Yang*, Shuhui Yang, Zebin He, Xintong Han, Hongbo Fu, Chunchao Guo, Wenhan Luo,
European Conference on Computer Vision (ECCV), 2026.
[arXiv] [Project Page] [Code]

Peng Li, Rawal Khirodkar, Junxuan Li, Yuan Dong, Chen Cao, Yuan Liu, Wenhan Luo, Yike Guo, Shunsuke Saito,
European Conference on Computer Vision (ECCV), 2026.
[arXiv] [Project Page]

Yanqin Jiang, Tengfei Wang, Zhenwei Wang, Chenjie Cao, Junta Wu, Wenhan Luo, Weiming Hu, Jin Gao, Chunchao Guo,
European Conference on Computer Vision (ECCV), 2026.
[arXiv] [Project Page] [Code] [Hugging Face Model]

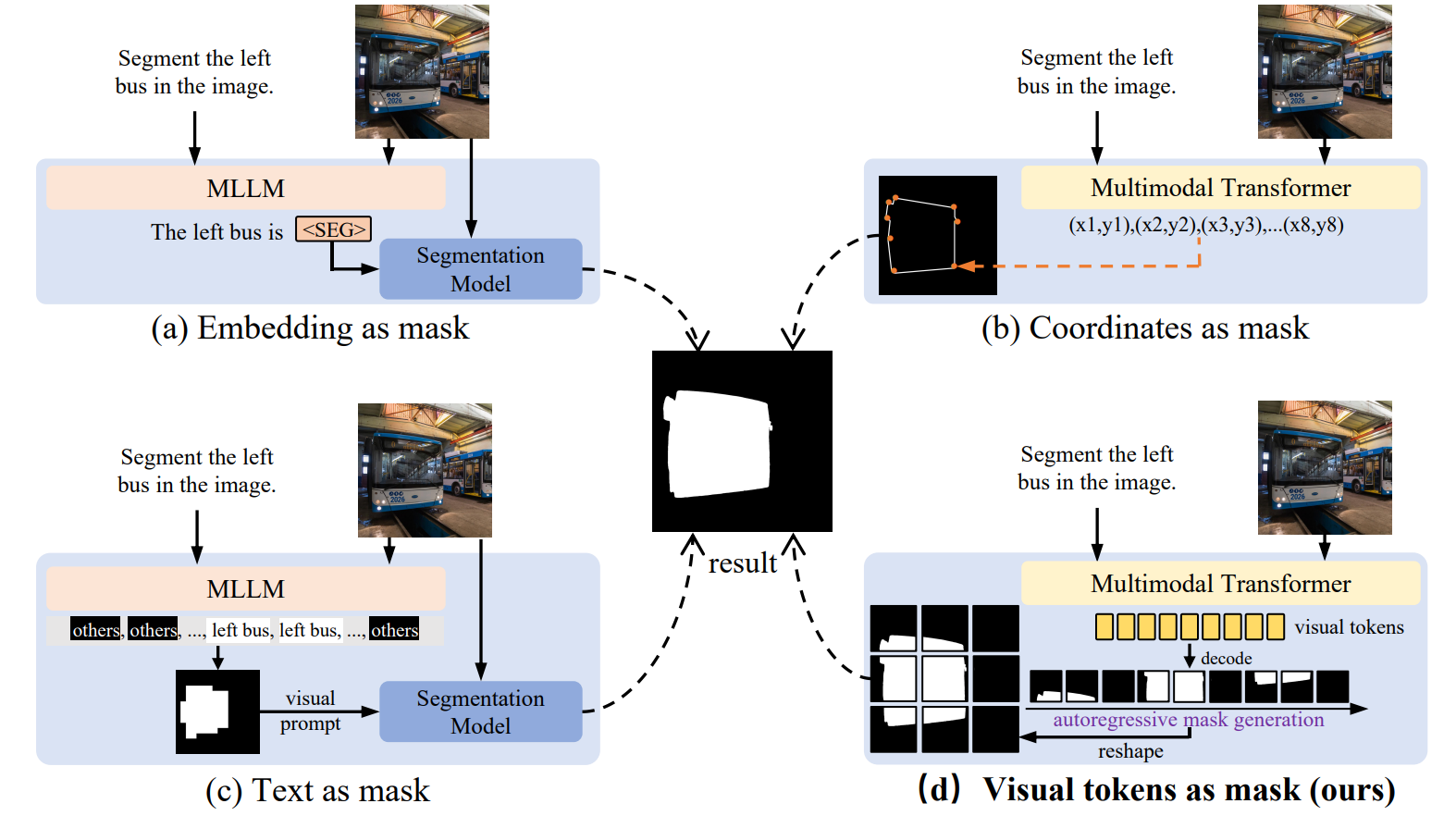
Jiru Deng, Tengjin Weng, Tianyu Yang, Wenhan Luo, Zhiheng Li, Wenhao Jiang,
European Conference on Computer Vision (ECCV), 2026.
[arXiv] [Code]
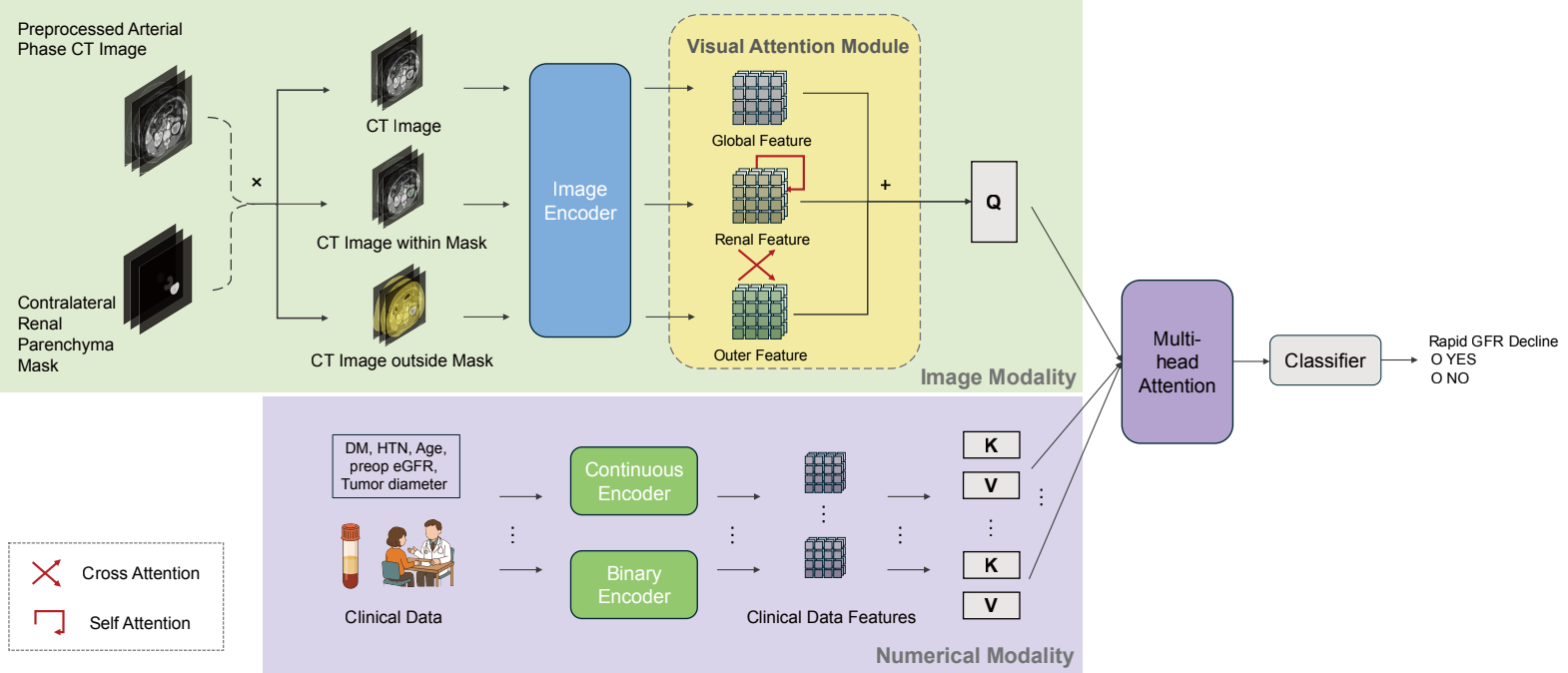
Yunhan Luo*, Yatian Wang*, Xiangpeng Zou*, Shiying Tang*, Xin Luo, Zhaohui Zhou, Longbin Xiong, Yulu Peng, Chunsen Yang, Ning Wang, Haitian Song, Gaoyu Zou, Jinhao Shi, Xiangyu Zi, Ming Gao, Nan Jia, Ping Yang, Fengfeng Yang, Zaosong Zheng, Peng Wu, Wen Dong, Pei Dong, Shengjie Guo, Hui Han, Shimiao Zhu, Jinchao Chen, Junhang Luo, Wei Zhai, Yawen Xu, Jianhui Chen, Yu Fan, Le Qu, Xiaonan Chen, Jiaxin Zhuang, Hao Chen, Chunping Yu, Xuepei Zhang, Qifeng Liu, Fangjian Zhou, Shudong Zhang, Wenhan Luo, Xin Yao, Zhiling Zhang,
Nature Communications, 2026.
[PDF]
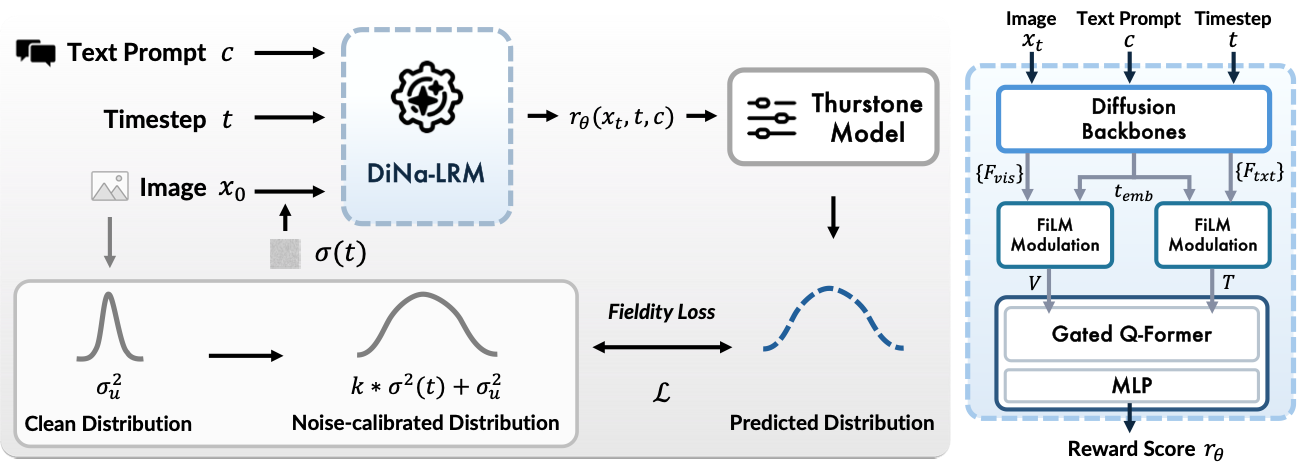
Gongye Liu, Bo Yang, Yida Zhi, Zhizhou Zhong, Lei Ke, Didan Deng, Han Gao, Yongxiang Huang, Kaihao Zhang, Hongbo Fu, Wenhan Luo,
International Conference on Machine Learning (ICML), 2026.
[arXiv] [Code]


Zixuan Ye, Quande Liu, Cong Wei, Yuanxing Zhang, Xintao Wang, Pengfei Wan, Kun Gai, Wenhan Luo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026.
[arXiv] [Project Page]
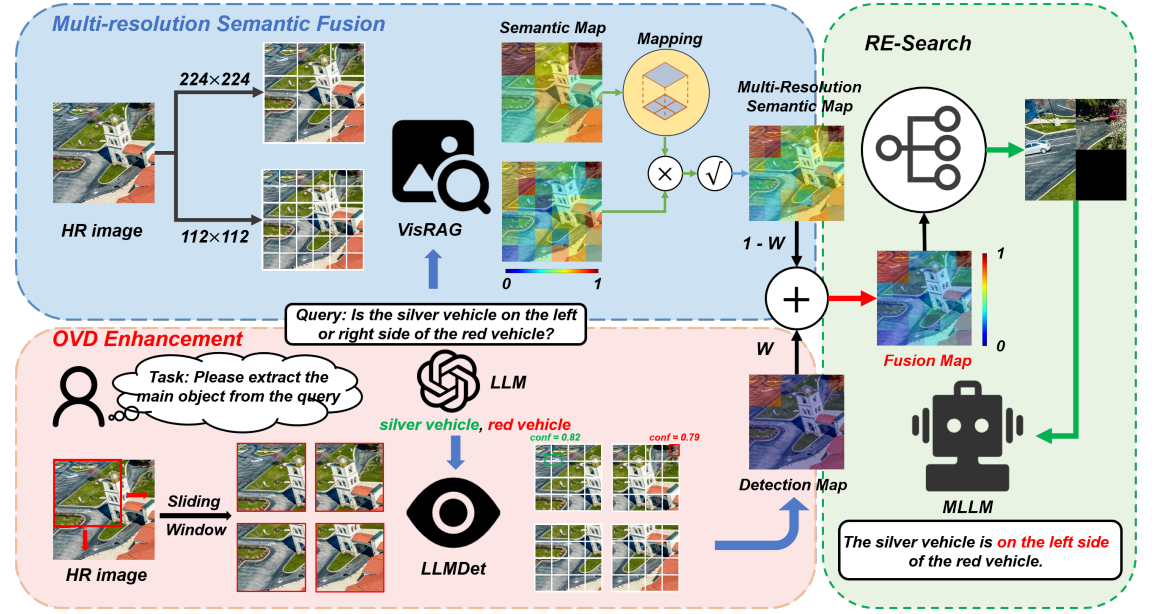
Fan Yang, Xingping Dong, Xin Yu, Wenhan Luo, Wei Liu, Kaihao Zhang,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026.
[arXiv]
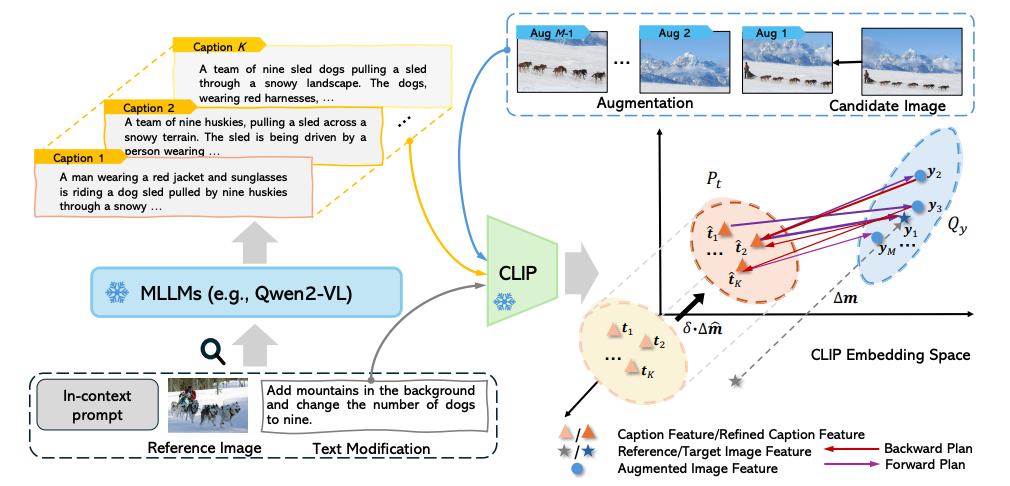
Miaoge Li, Dongsheng Wang, Zening Sun, Jinsen Zhang, Wenhan Luo, Jingcai Guo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026.
[arXiv]
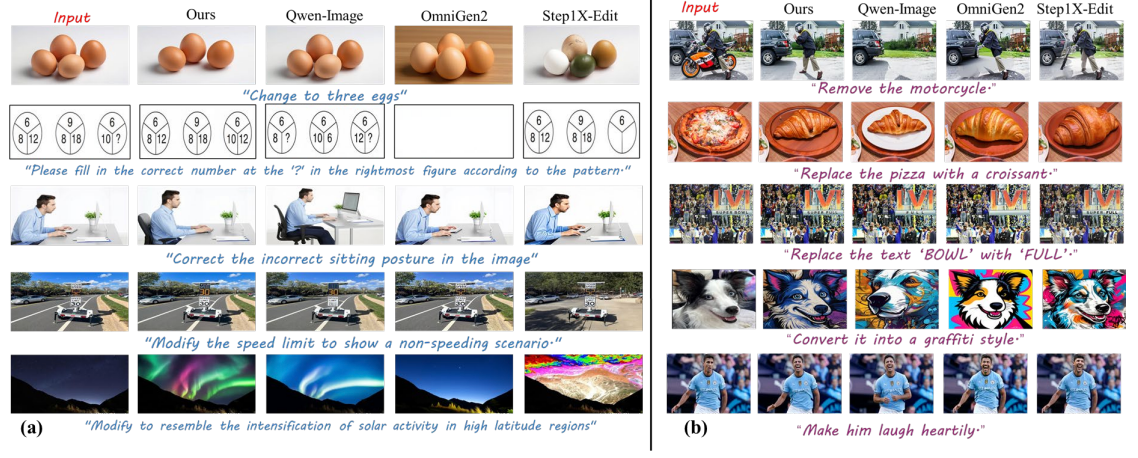
Yan Li, Lin Liu, Xiaopeng Zhang, Wei Xue, Wenhan Luo, Yike Guo, Qi Tian,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026.
[arXiv]

Mengfei Li, Peng Li, Zheng Zhang, Jiahao Lu, Chengfeng Zhao, Wei Xue, Qifeng Liu, Sida Peng, Wenxiao ZHANG, Wenhan Luo, Yuan Liu, Yike Guo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026.
[arXiv] [Project Page] [Code]


Lei Ke, Hubery Yin, Gongye Liu, Zhengyao Lv, Jingcai Guo, Chen Li, Wenhan Luo, Yujiu Yang, Jing Lyu,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026.
[arXiv]

Zixuan Ye, Xuanhua He, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Qifeng Chen, Wenhan Luo,
International Conference on Learning Representations (ICLR), 2026.
[arXiv] [Project Page]
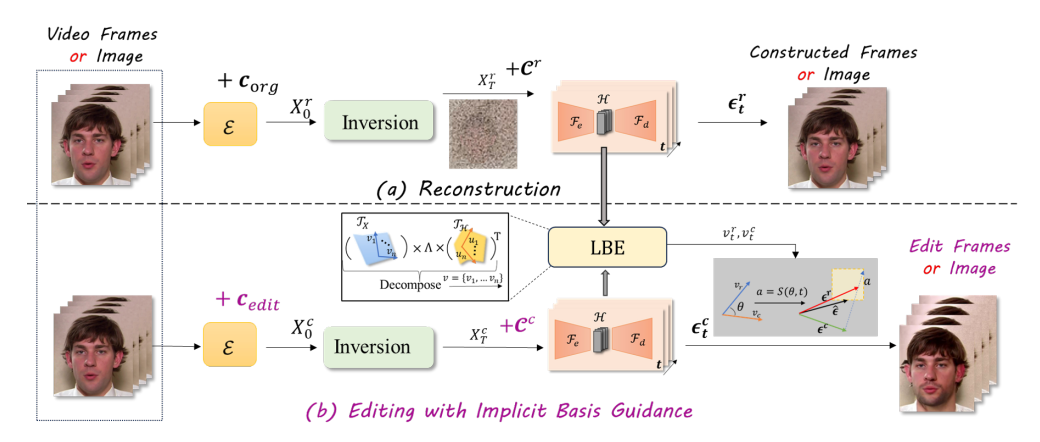
Yan Li, Zhenyi Wang, Guanghao Li, Wei Xue, Wenhan Luo, Yike Guo,
International Conference on Learning Representations (ICLR), 2026.
[OpenReview Link]

Xinyu Liu, Yingqing He, Lanqing Guo, Xiang Li, Bu Jin, Yan Li, Chi-Min Chan, Wei Xue, Wenhan Luo, Qifeng Liu, Yike Guo,
International Journal of Computer Vision (IJCV), vol. 134, 2026.
[arXiv] [Project Page] [Code]

Zhe Kong, Feng Gao, Yong Zhang, Zhuoliang Kang, Xiaoming Wei, Xunliang Cai, Guanying Chen, Wenhan Luo,
Neural Information Processing Systems (NeurIPS), 2025.
[arXiv] [Project Page] [Code] [Hugging Face Model] [Gradio]


Yiyang Cai, Zhengkai Jiang, Yulong Liu, Chunyang Jiang, Wei Xue, Yike Guo, Wenhan Luo,
Neural Information Processing Systems (NeurIPS), 2025.
[PDF] [Project Page] [Code]


Zebin He, Mingxin Yang, Shuhui Yang, Yixuan Tang, Tao Wang, Kaihao Zhang, Guanying Chen, Yuhong Liu, Jie Jiang, Chunchao Guo, Wenhan Luo,
Proc. of International Conference on Computer Vision (ICCV), Hawaii, USA, 2025. (Highlight)
[arXiv] [Project Page] [Code]


Tao Wang, Peiwen Xia, Bo Li, Peng-Tao Jiang, Zhe Kong, Kaihao Zhang, Tong Lu, Wenhan Luo,
Proc. of International Conference on Computer Vision (ICCV), Hawaii, USA, 2025.
[PDF]

Renxiang Guan, Tianrui Liu, Wenxuan Tu, Chang Tang, Wenhan Luo, Xinwang Liu
IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 37, pp. 5598-5612, 2025.
[PDF]

Mengfei Li, Xiaoxiao Long, Yixun Liang, Weiyu Li, Yuan Liu, Peng Li, Wenhan Luo, Wenping Wang, Yike Guo,
IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 31, pp. 8564-8577, 2025.
[arXiv] [Project Page] [Code]


Xinyu Chen, Yunxin Li, Haoyuan Shi, Baotian Hu, Wenhan Luo, Yaowei Wang, Min Zhang,
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025.
[arXiv] [Project Page] [Github] [Hugging Face]

Zhe Kong, Le Li, Yong Zhang, Feng Gao, Shaoshu Yang, Tao Wang, Kaihao Zhang, Zhuoliang Kang, Xiaoming Wei, Guanying Chen, Wenhan Luo,
ACM SIGGRAPH, 2025.
[PDF] [Project Page] [Code]

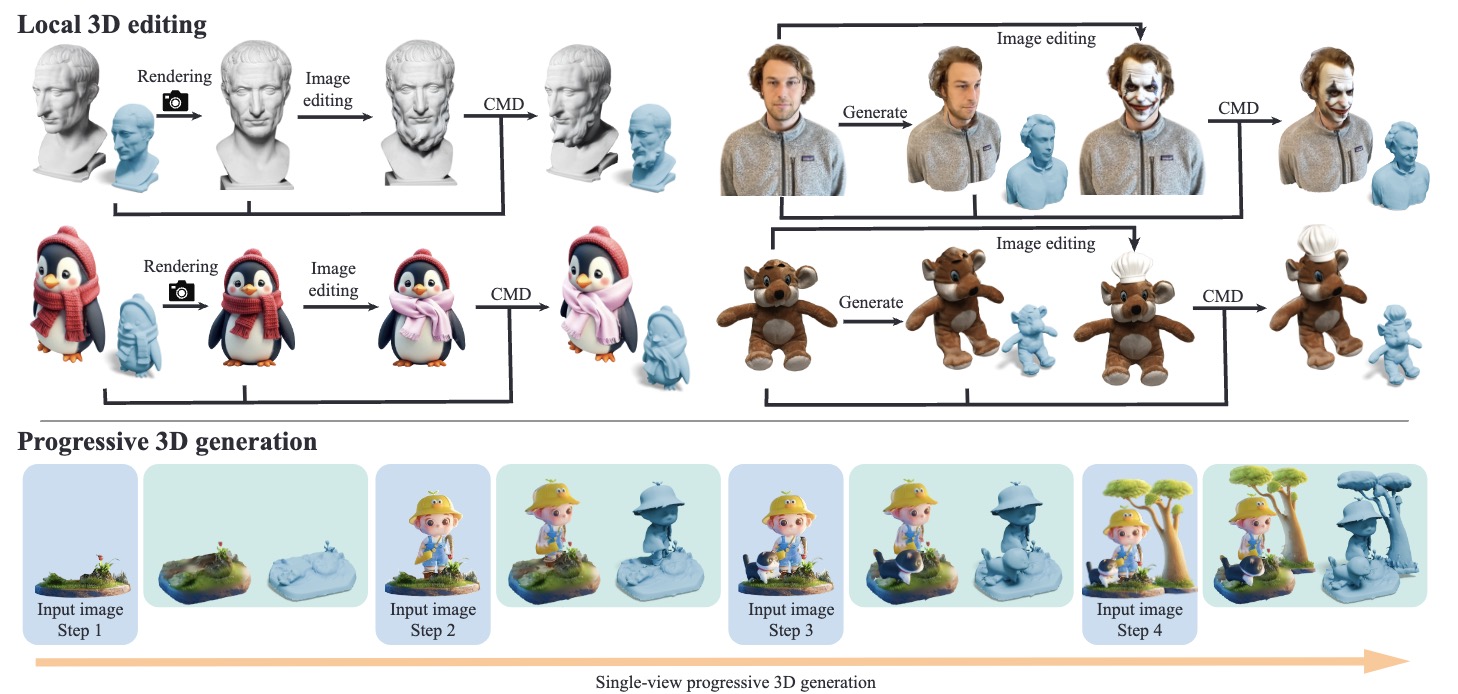
Peng Li, Suizhi Ma, Jialiang Chen, Yuan Liu, Congyi Zhang, Wei Xue, Wenhan Luo, Alla Sheffer, Wenping Wang, Yike Guo,
ACM SIGGRAPH, 2025.
[PDF] [Project Page]

Zhi Jin, Yuwei Qiu, Kaihao Zhang, Hongdong Li, Wenhan Luo,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), vol. 47, pp. 5990–6005, 2025. (Highly Cited Paper & Hot Paper)
[arXiv] [Code]

Tao Wang, Kaihao Zhang, Yong Zhang, Wenhan Luo, Bjorn Stenger, Tong Lu, Tae-Kyun Kim, Wei Liu, Hongdong Li,
Pattern Recognition, vol. 166, pp. 111628, 2025. (Highly Cited Paper & Hot Paper)
[arXiv] [Code]

Zixuan Ye, Huijuan Huang, Xintao Wang, Pengfei Wan, Di Zhang, Wenhan Luo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025.
[arXiv] [Github] [Project Page]


Peng Li, Wangguandong Zheng, Yuan Liu, Tao Yu, Yangguang Li, Xingqun Qi, Xiaowei Chi, Siyu Xia, Yan-Pei Cao, Wei Xue, Wenhan Luo, Yike Guo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025.
[arXiv] [Github] [Project Page] [Hugging Face Demo]


Xiaofeng Mao, Zhengkai Jiang, Fu-Yun Wang, Jiangning Zhang, Hao Chen, Mingmin Chi, Yabiao Wang, Wenhan Luo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025.
[PDF]

Jingyun Xue, Hongfa Wang, Qi Tian, Yue Ma, Andong Wang, Zhiyuan Zhao, Shaobo Min, Wenzhe Zhao, Kaihao Zhang, Heung-Yeung Shum, Wei Liu, Mengyang Liu, Wenhan Luo,
International Conference on Learning Representations (ICLR), 2025.
[PDF] [Project Page] [API in Tencent Cloud]

Xingqun Qi, Yatian Wang, Hengyuan Zhang, Jiahao Pan, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo,
International Conference on Learning Representations (ICLR), 2025.
[PDF] [Project Page]

Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), vol. 47, pp. 3424-3439, 2025.
[arXiv] [Code] [Project Page] [Model]


Peng Li, Yuan Liu, Xiaoxiao Long, Feihu Zhang, Cheng Lin, Mengfei Li, Xingqun Qi, Shanghang Zhang, Wenhan Luo, Ping Tan, Wenping Wang, Qifeng Liu, Yike Guo,
Neural Information Processing Systems (NeurIPS), 2024.
[arXiv] [Code] [Project Page] [Hugging Face Demo] [Model]

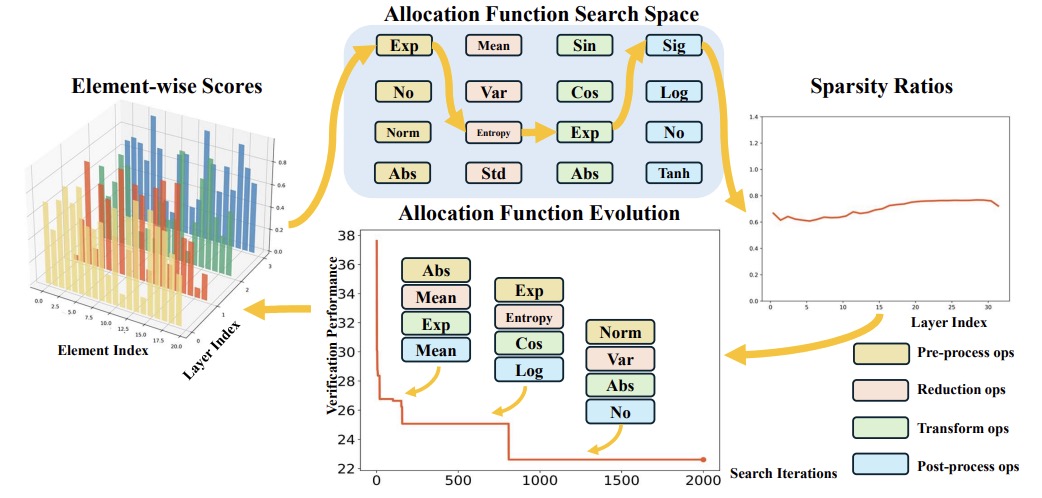
Lujun Li, Peijie Dong, Zhenheng Tang, Xiang Liu, Qiang Wang, Wenhan Luo, Wei Xue, Qifeng Liu, Xiaowen Chu, Yike Guo,
Neural Information Processing Systems (NeurIPS), 2024.
[PDF]
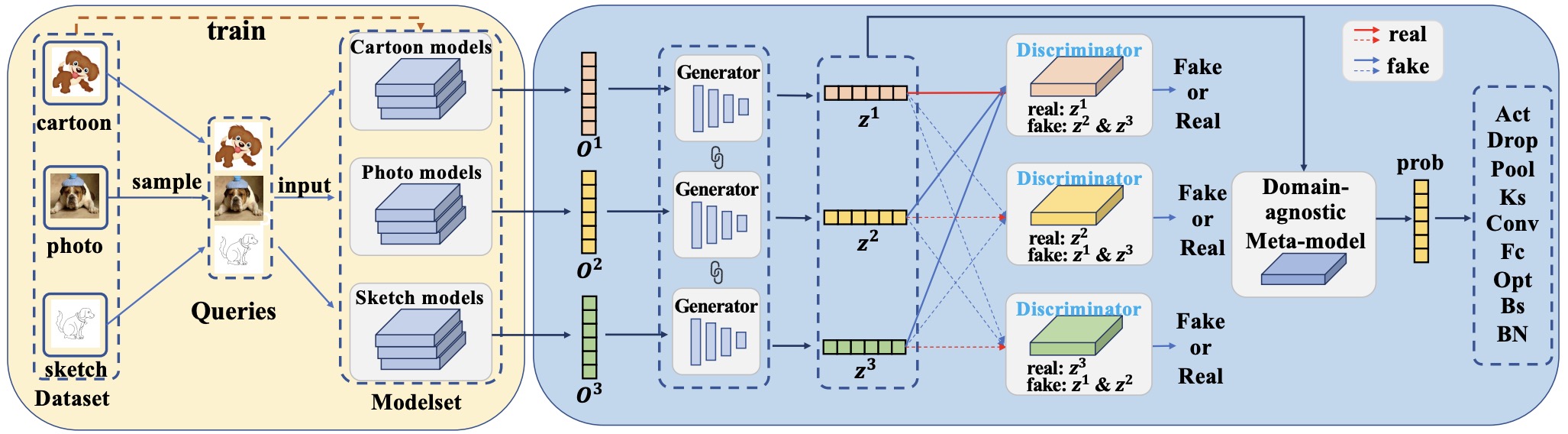
Rongqing Li, Jiaqi Yu, Changsheng Li, Wenhan Luo, Ye Yuan, Guoren Wang,
IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 36, pp. 8009-8022, 2024.
[PDF]

Tao Zhou, Qi Ye, Wenhan Luo, Haizhou Ran, Zhiguo Shi, Jiming Chen,
International Journal of Computer Vision (IJCV), vol. 133, pp. 2044–2069, 2024.
[PDF]
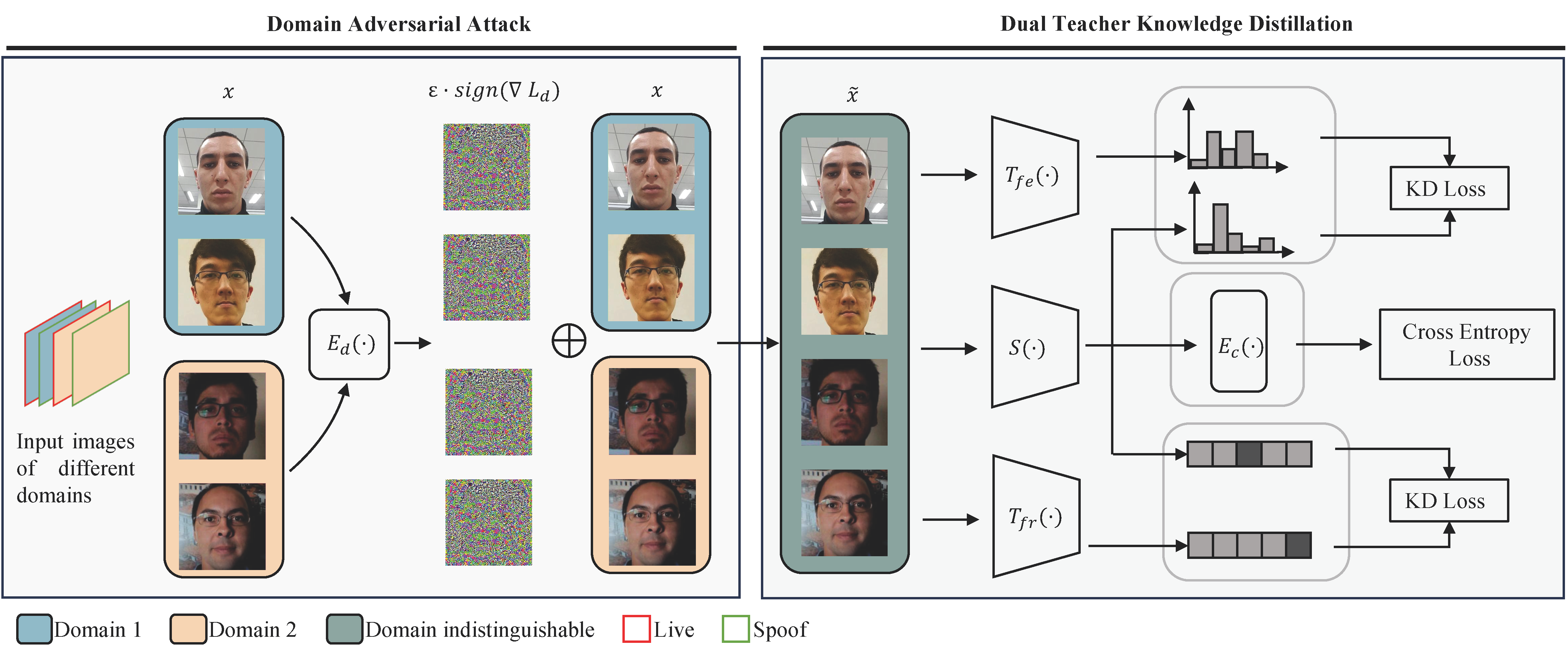
Zhe Kong, Wentian Zhang, Tao Wang, Kaihao Zhang, Yuexiang Li, Xiaoying Tang, Wenhan Luo,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), vol. 34, pp. 13177-13189, 2024.
[PDF]
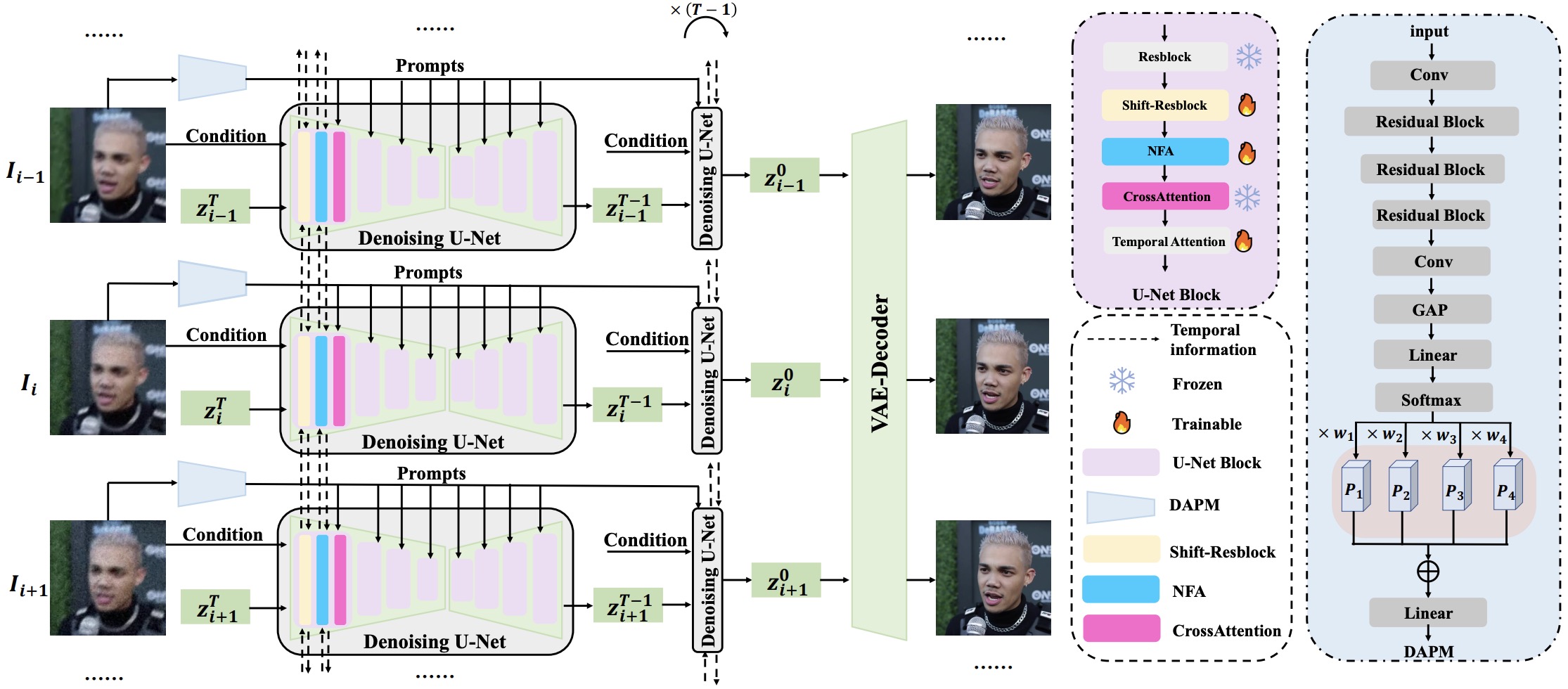
Jingfan Tan, Hyunhee Park, Ying Zhang, Tao Wang, Kaihao Zhang, Xiangyu Kong, Pengwen Dai, Zikun Liu, Wenhan Luo,
The 32rd ACM International Conference on Multimedia (ACM MM), 2024.
[PDF]

Zhe Kong, Yong Zhang, Tianyu Yang, Tao Wang, Kaihao Zhang, Bizhu Wu, Guanying Chen, Wei Liu, Wenhan Luo,
European Conference on Computer Vision (ECCV), 2024.
[PDF] [Code] [Project Page] [Hugging Face (OMG+LoRAs)] [Hugging Face (OMG+InstantID)]

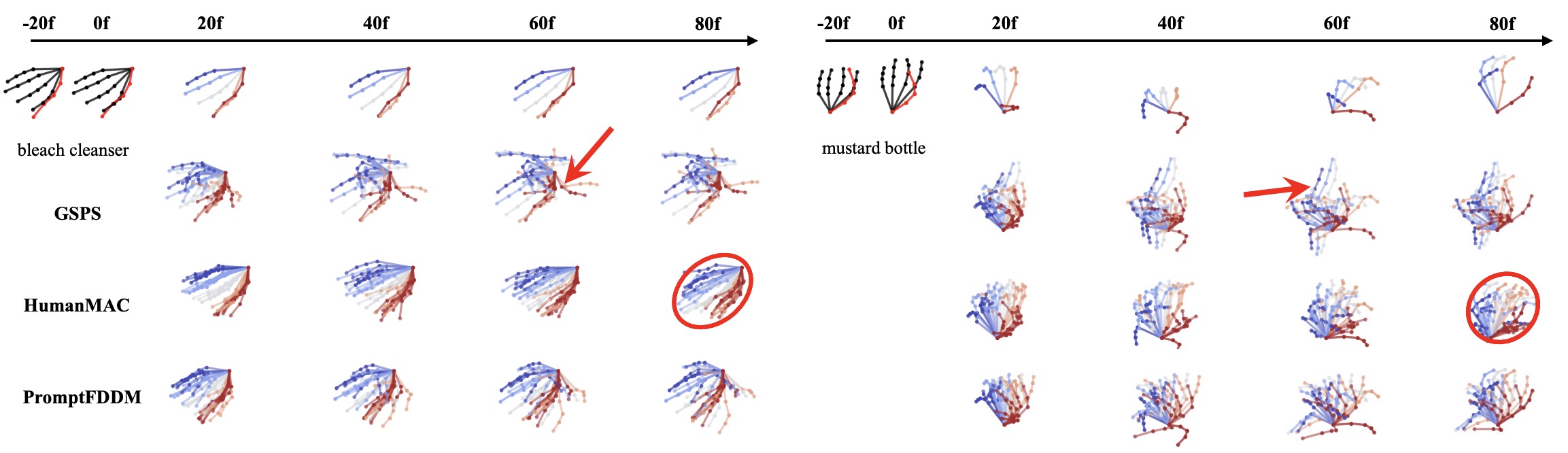
Bowen Tang, Kaihao Zhang, Wenhan Luo, Wei Liu, Hongdong Li,
European Conference on Computer Vision (ECCV), 2024.
[PDF]

Lujun Li, Haosen Sun, Shiwen Li, Peijie Dong, Wenhan Luo, Wei Xue, Qifeng Liu, Yike Guo,
European Conference on Computer Vision (ECCV), 2024.
[PDF]
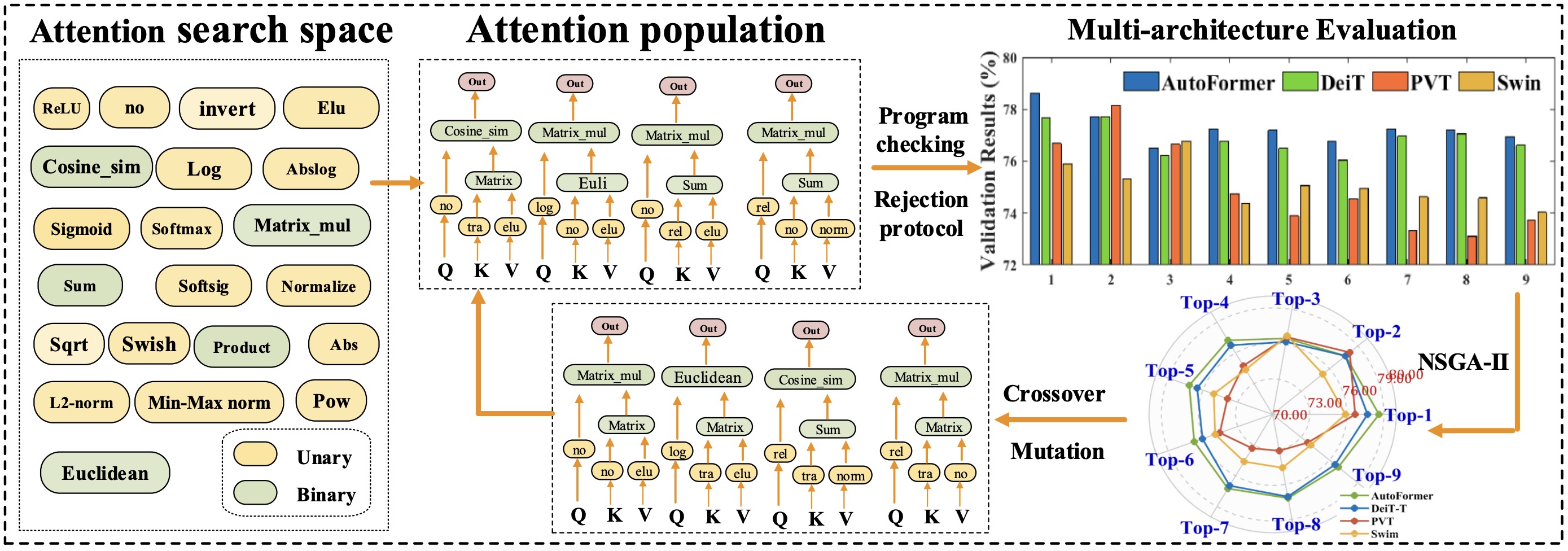
Lujun Li, Zimian Wei, Peijie Dong, Wenhan Luo, Wei Xue, Qifeng Liu, Yike Guo,
European Conference on Computer Vision (ECCV), 2024.
[PDF]
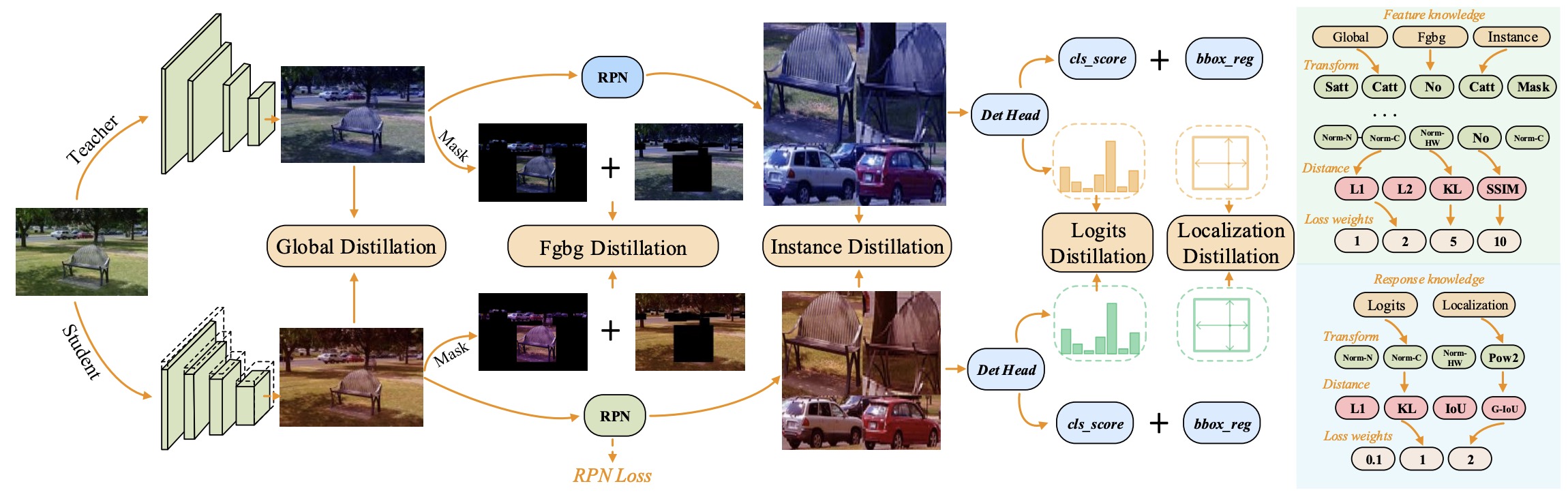
Lujun Li, Yufan Bao, Peijie Dong, Chuanguang Yang, Anggeng Li, Wenhan Luo, Qifeng Liu, Wei Xue, Yike Guo,
International Conference on Machine Learning (ICML), 2024.
[PDF]
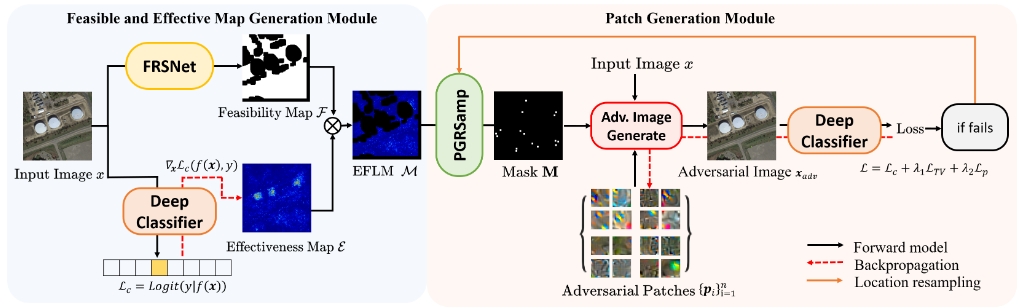
Jun-Jie Huang, Ziyue Wang, Tianrui Liu, Wenhan Luo, Zihan Chen, Wentao Zhao, Meng Wang,
IEEE Trans. on Geoscience and Remote Sensing, vol. 62, pp. 1-13, 2024.
[PDF]

Xiaoxu Chen, Jingfan Tan, Tao Wang, Kaihao Zhang, Wenhan Luo, Xiaochun Cao,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), vol. 34, pp. 8494-8508, 2024.
[PDF] [Code]


Tao Wang, Kaihao Zhang, Ziqian Shao, Wenhan Luo, Bjorn Stenger, Tong Lu, Tae-Kyun Kim, Wei Liu, Hongdong Li,
International Journal of Computer Vision (IJCV), vol. 132, pp. 4541-4563, 2024. (Highly Cited Paper & Hot Paper)
[PDF] [Code]
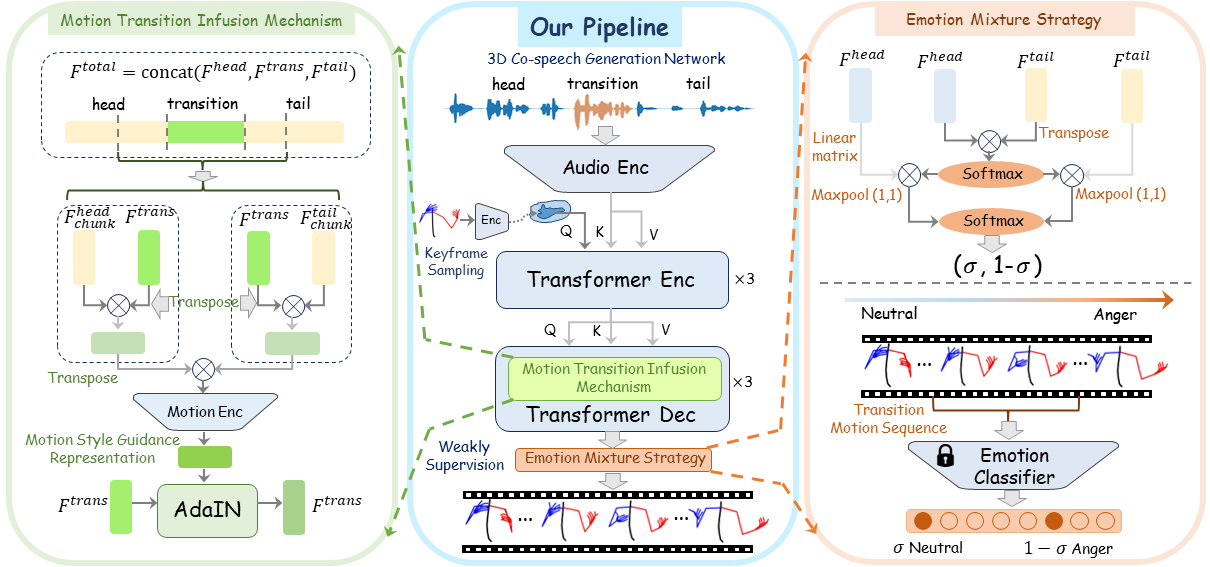
Xingqun Qi, Jiahao Pan, Peng Li, Ruibin Yuan, Xiaowei Chi, Mengfei Li, Wenhan Luo, Wei Xue, Shanghang Zhang, Qifeng Liu, Yike Guo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2024.
[PDF] [Project Page]
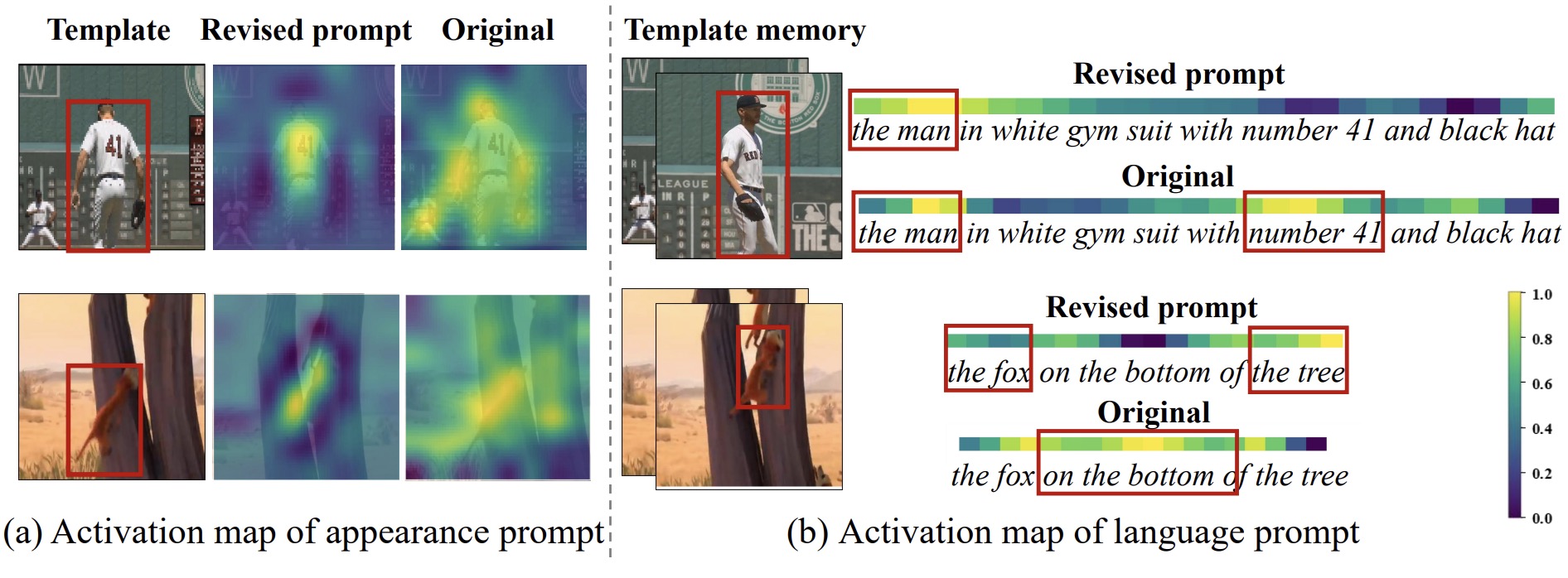
Yanyan Shao, Shuting He, Qi Ye, Yuchao Feng, Wenhan Luo, Jiming Chen,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2024.
[PDF]

Yunxin Li, Baotian Hu, Wenhan Luo, Lin Ma, Yuxin Ding, Min Zhang,
LREC-COLING, 2024.
[PDF] [Dataset]
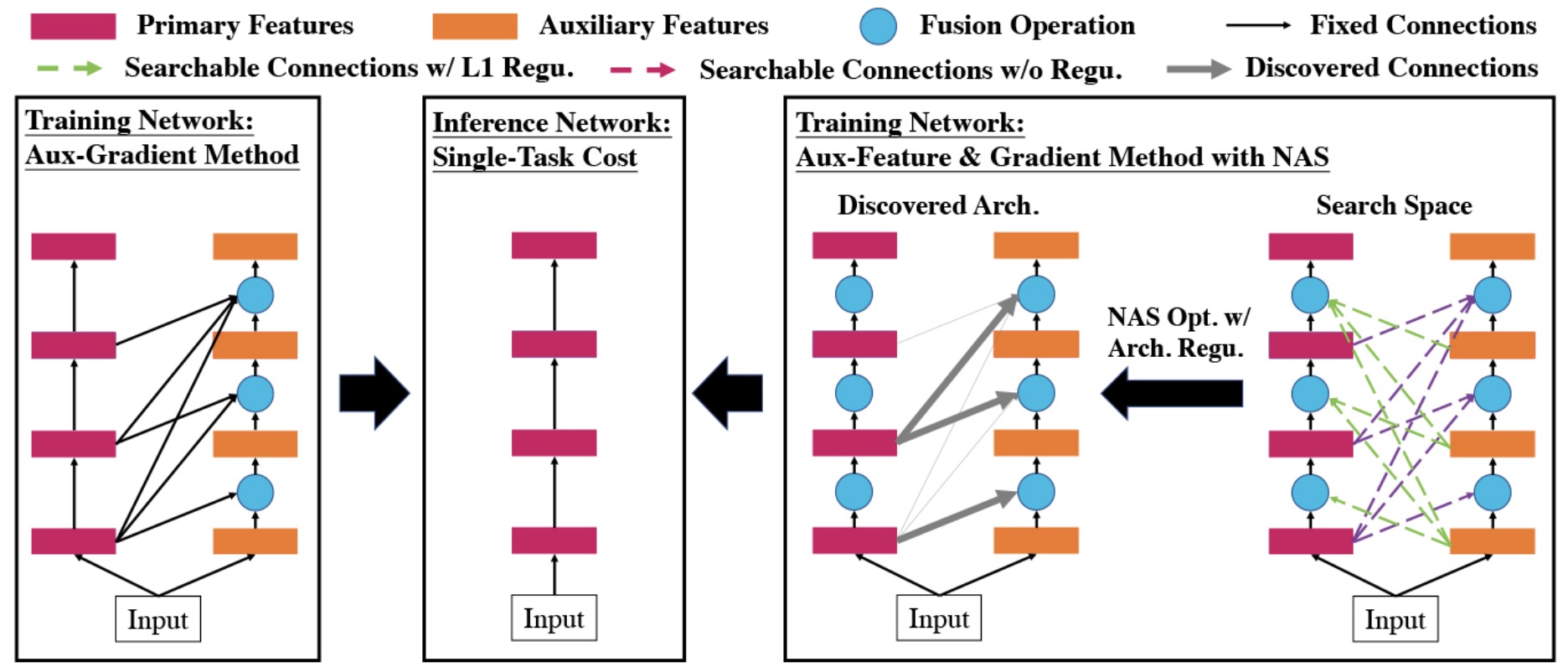
Yuan Gao, Weizhong Zhang, Wenhan Luo, Lin Ma, Jin-Gang Yu, Gui-Song Xia, Jiayi Ma,
International Conference on Learning Representations (ICLR), 2024.
[PDF]

Yanjiang Yu, Puyang Zhang, Kaihao Zhang, Wenhan Luo, Changsheng Li, Ye Yuan, Guoren Wang,
IEEE Transactions on Neural Networks and Learning Systems (TNNLS), vol. 36, pp. 3057-3070, 2025.
[PDF] [Code]

Jingfan Tan, Xiaoxu Chen, Tao Wang, Kaihao Zhang, Wenhan Luo, Xiaochun Cao,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), vol. 34, pp. 4914-4927, 2024.
[PDF]

Wenqiang Wang, Chongyang Du, Tao Wang, Kaihao Zhang, Wenhan Luo, Lin Ma, Wei Liu, Xiaochun Cao,
Neural Information Processing Systems (NeurIPS), 2023.
[PDF]

Kaihao Zhang, Tao Wang, Wenhan Luo, Wenqi Ren, Bjorn Stenger, Wei Liu, Hongdong Li, Ming-Hsuan Yang,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), vol. 34, pp. 3755-3767, 2024. (Highly Cited Paper & Hot Paper)
[PDF] [Dataset]

Tao Wang, Guangpin Tao, Wanglong Lu, Kaihao Zhang, Wenhan Luo, Xiaoqin Zhang, Tong Lu,
Pattern Recognition, vol. 145, pp. 109956, 2024.
[PDF]

Tao Gao, Yuanbo Wen, Kaihao Zhang, Jing Zhang, Ting Chen, Lidong Liu, Wenhan Luo,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), vol. 34, pp. 1886-1899, 2024. (Highly Cited Paper)
[PDF]

Tao Zhou, Qi Ye, Wenhan Luo, Kaihao Zhang, Zhiguo Shi, Jiming Chen,
Proc. of International Conference on Computer Vision (ICCV), Paris, France, 2023.
[PDF] [Project Page] [Code]
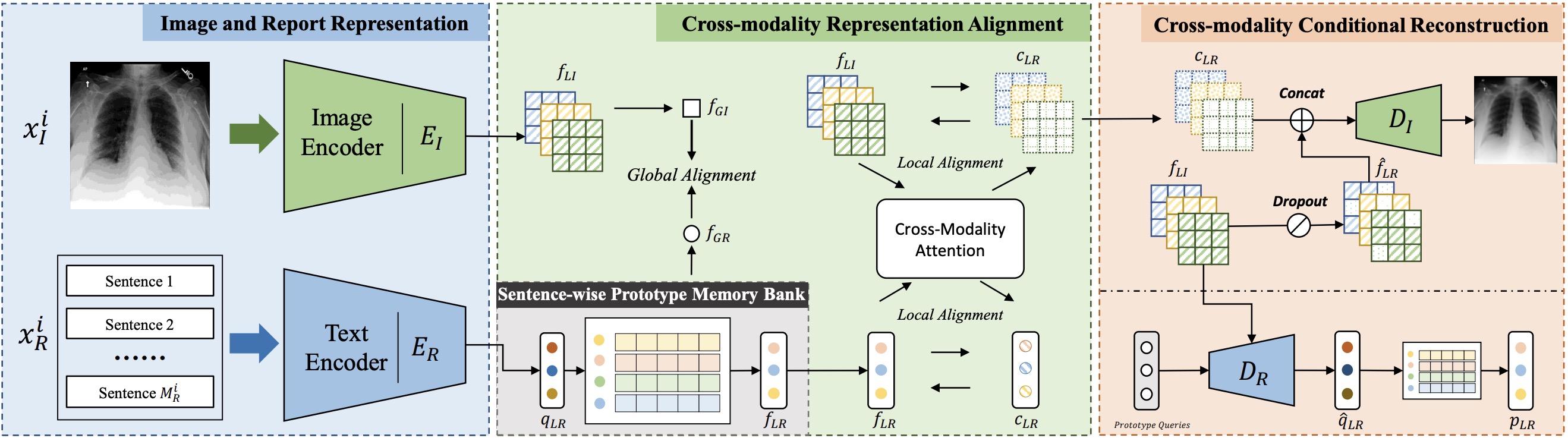
Pujin Cheng, Li Lin, Junyan Lyu, Yijin Huang, Wenhan Luo, Xiaoying Tang,
Proc. of International Conference on Computer Vision (ICCV), Paris, France, 2023.
[PDF] [Code]


Yuwei Qiu, Kaihao Zhang, Chenxi Wang, Wenhan Luo, Hongdong Li, Zhi Jin,
Proc. of International Conference on Computer Vision (ICCV), Paris, France, 2023.
[PDF] [Code]

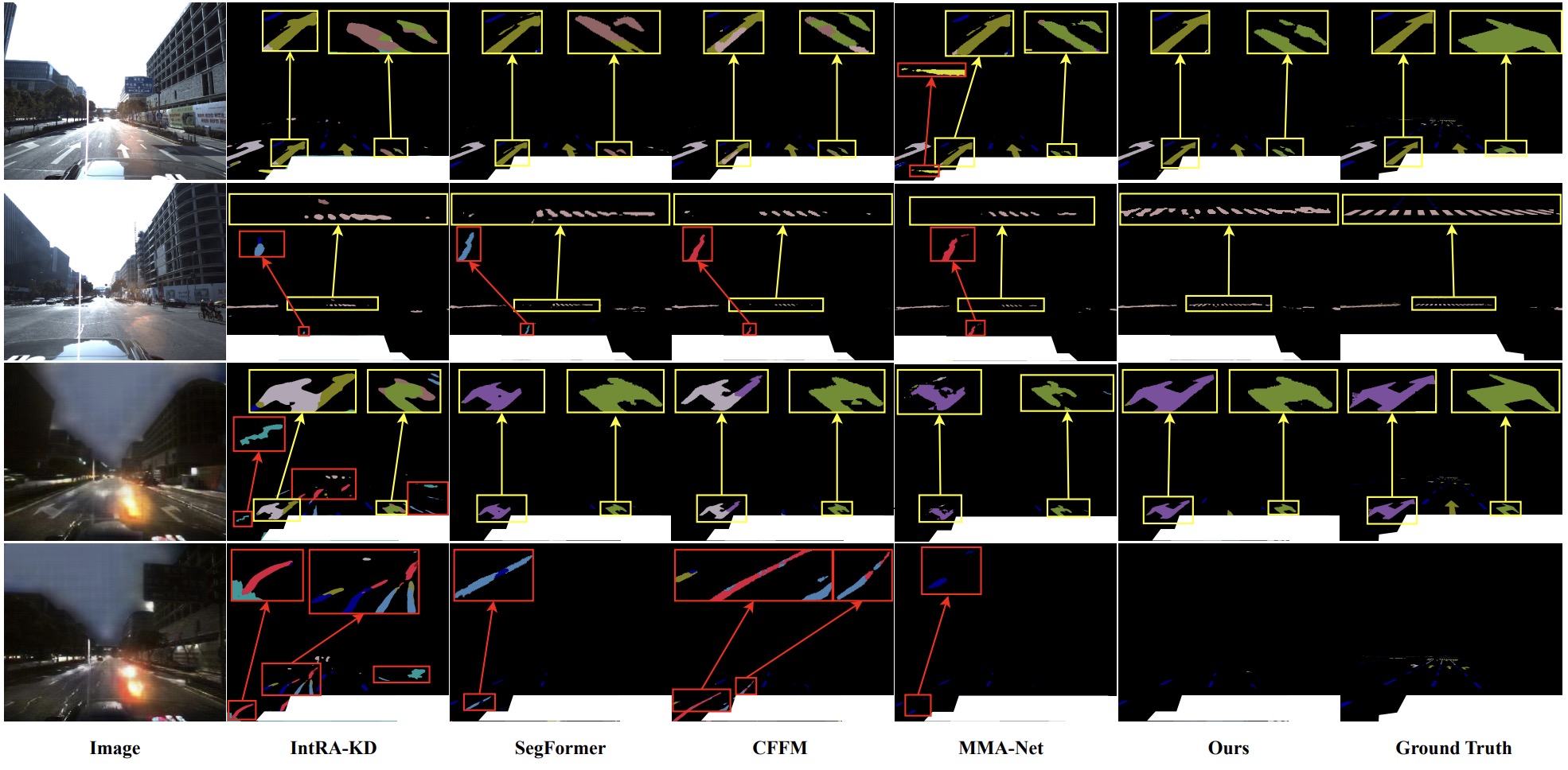
Shan Wang, Chuong Nguyen, Jiawei Liu, Kaihao Zhang, Wenhan Luo, Yanhao Zhang, Sundaram Muthu, Fahira Afzal Maken, Hongdong Li,
Proc. of International Conference on Computer Vision (ICCV), Paris, France, 2023.
[PDF] [Code]
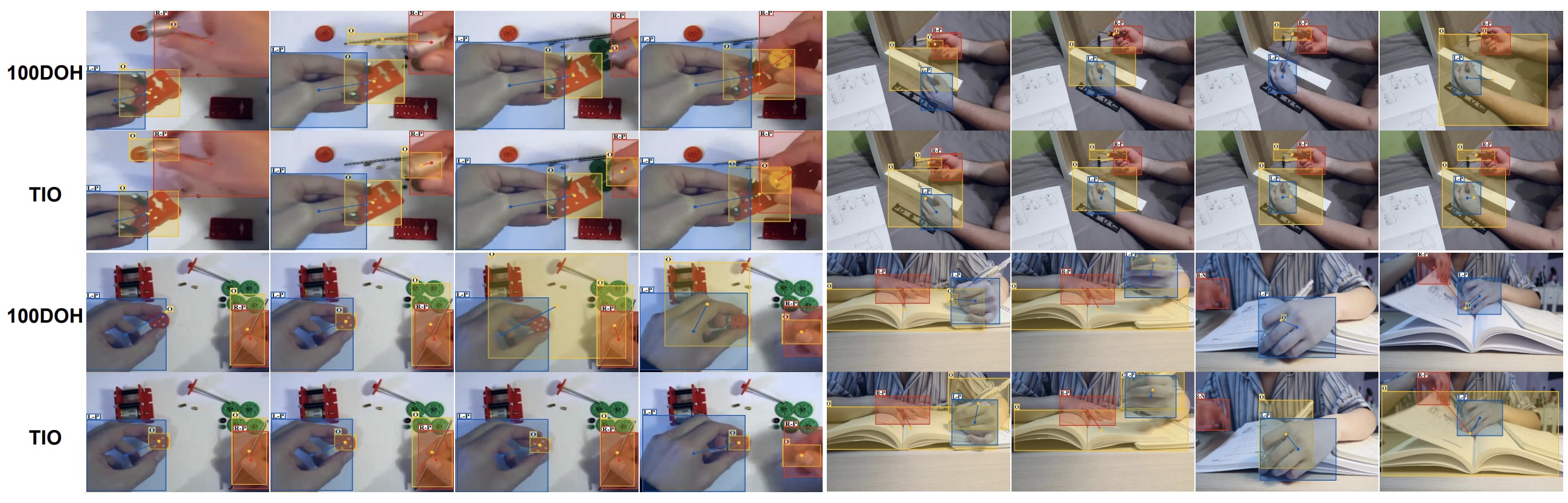
Yanyan Shao, Qi Ye, Wenhan Luo, Kaihao Zhang, Jiming Chen,
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023.
[PDF]
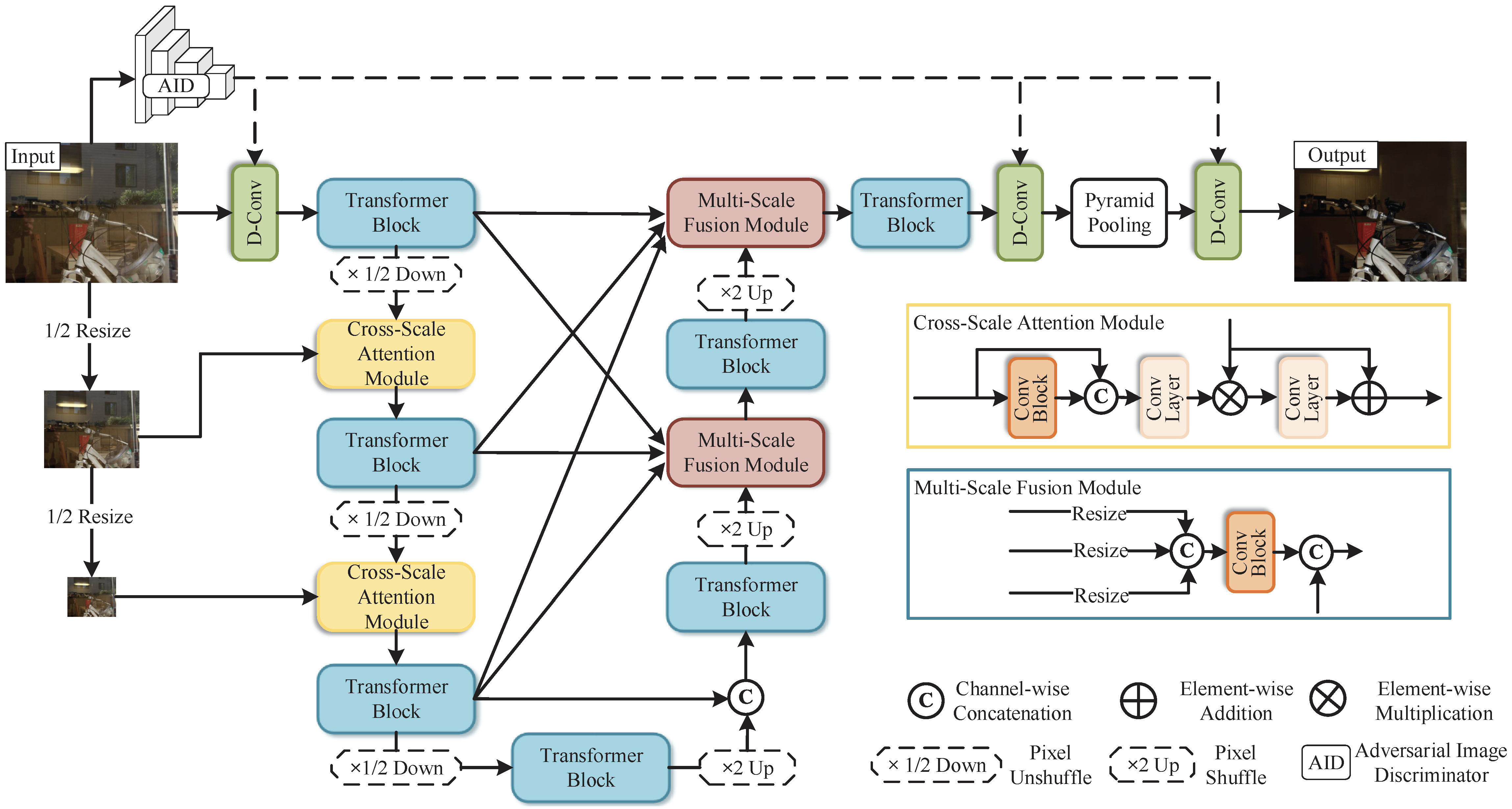
Zhenbo Song, Zhenyuan Zhang, Kaihao Zhang, Wenhan Luo, Zhaoxin Fan, Wenqi Ren, Jianfeng Lu,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2023.
[PDF] [Code]
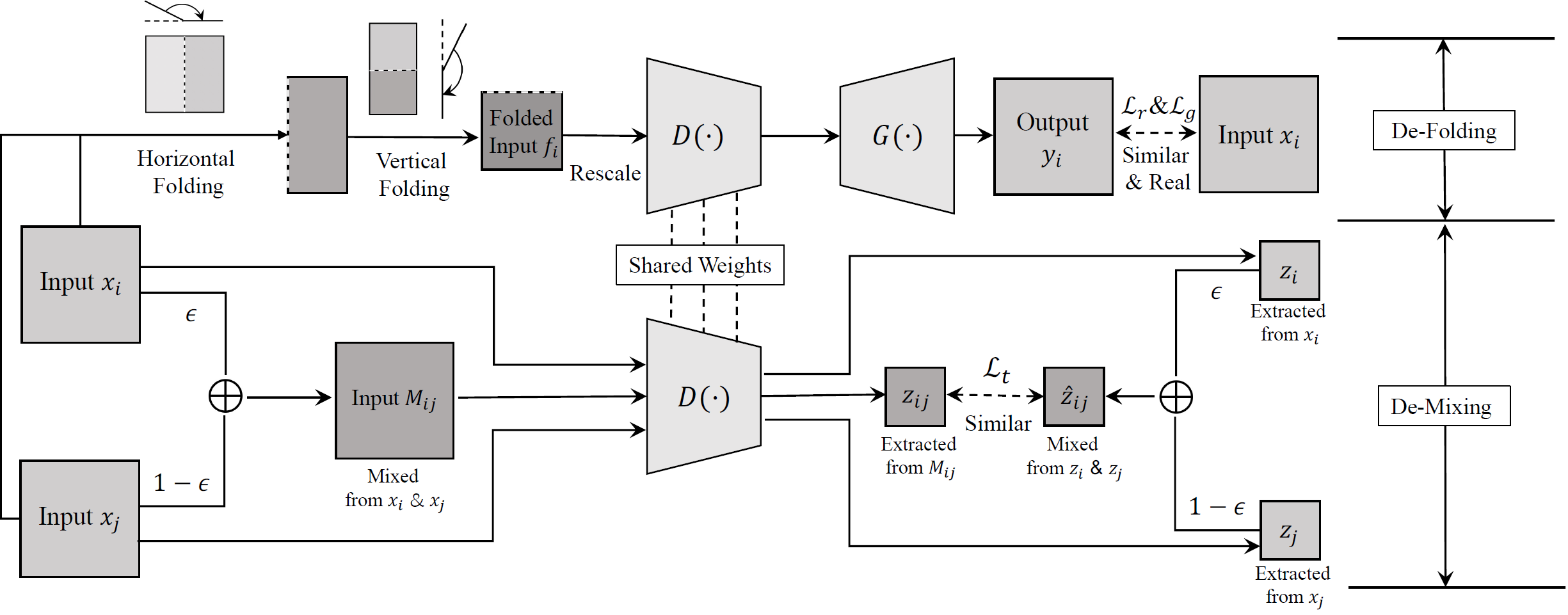
Zhe Kong, Wentian Zhang, Feng Liu, Wenhan Luo, Haozhe Liu, Linlin Shen, Raghavendra Ramachandra,
IEEE Transactions on Neural Networks and Learning Systems (TNNLS), vol. 35, pp. 10639-10650, 2024.
[PDF] [Code]
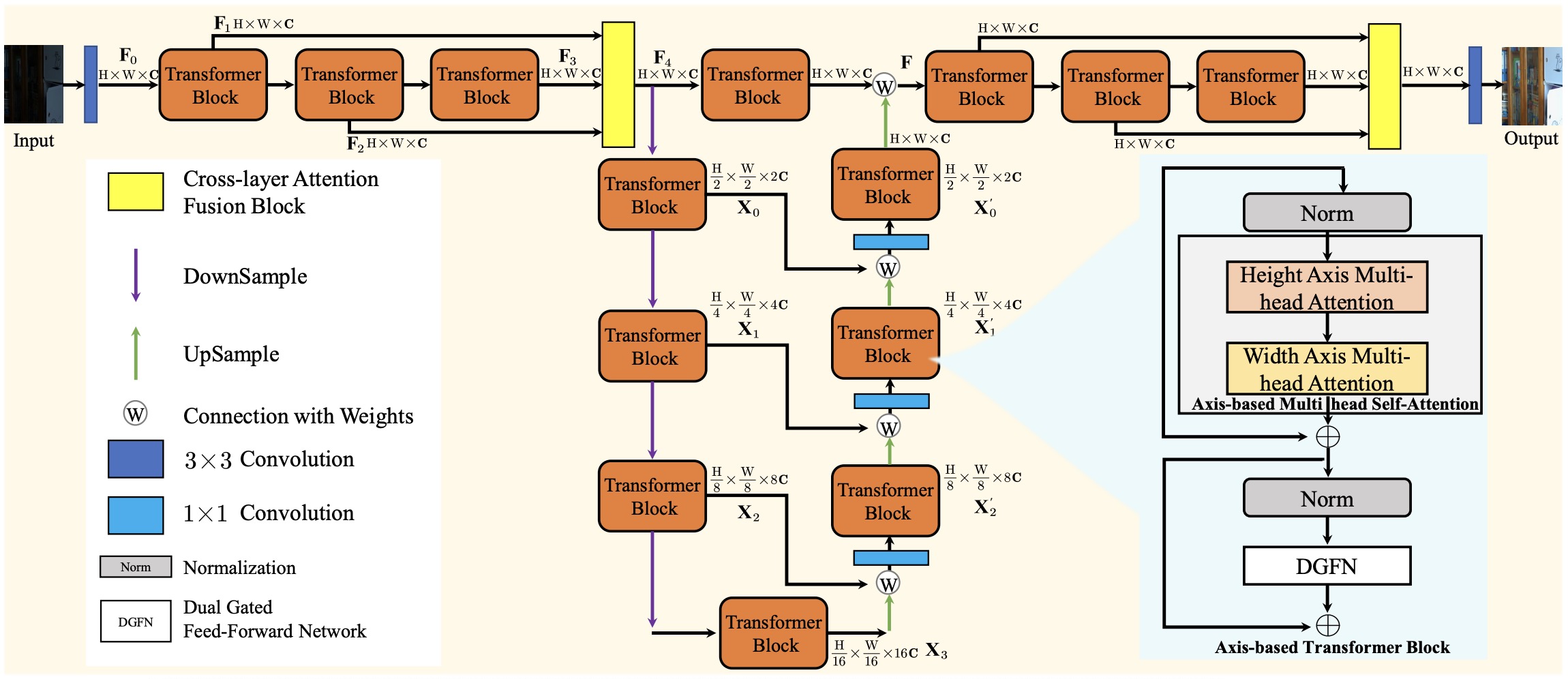
Tao Wang, Kaihao Zhang, Tianrun Shen, Wenhan Luo, Bjorn Stenger, Tong Lu,
Proc. of the Association for the Advancement of Artificial Intelligence (AAAI), USA, 2023. (Oral)
[PDF] [Code]

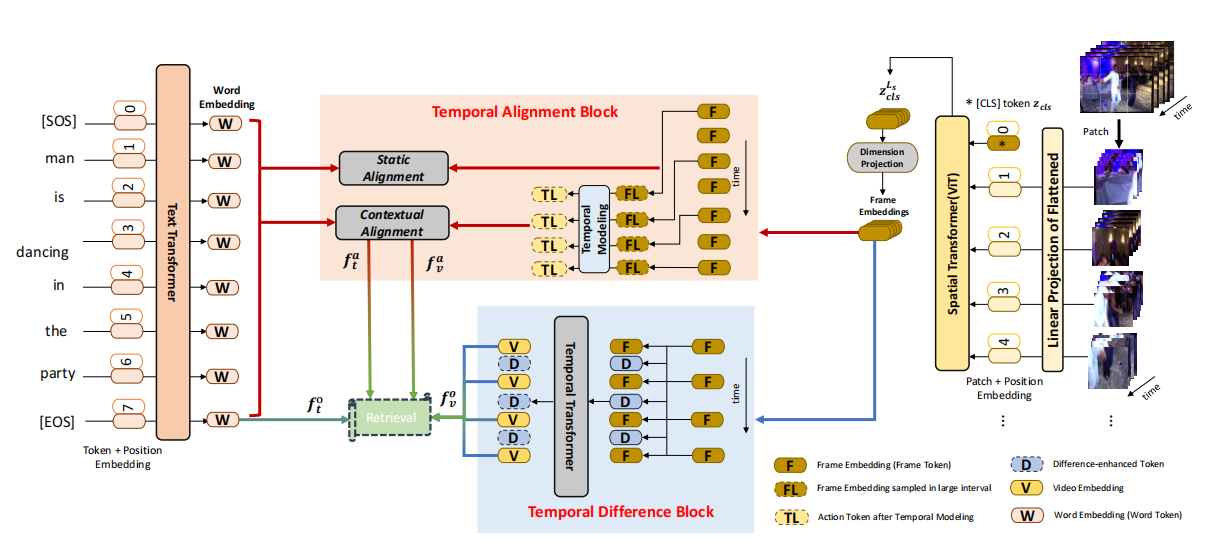
Han Fang, Pengfei Xiong, Luhui Xu, Wenhan Luo,
IEEE Transactions on Multimedia (TMM), vol. 25, pp. 7772-7785, 2023.
[PDF] [Code]


Lirong Zheng, Yanshan Li, Kaihao Zhang, Wenhan Luo,
IEEE Transactions on Multimedia (TMM), vol. 25, pp. 6794-6807, 2023.
[PDF]
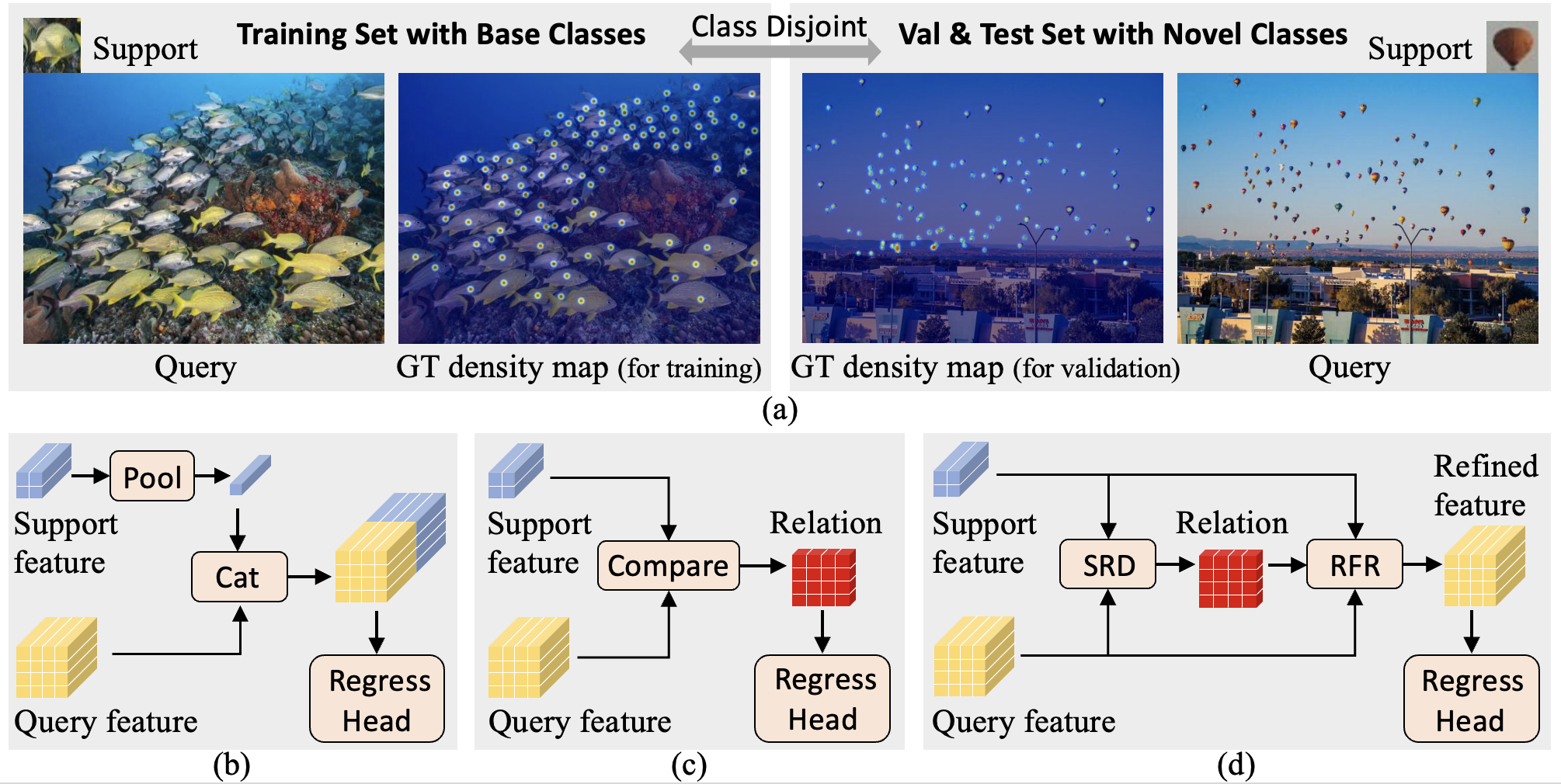
Zhiyuan You, Kai Yang, Wenhan Luo, Xin Lu, Lei Cui, Xinyi Le,
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023. (Oral)
[PDF] [Code]

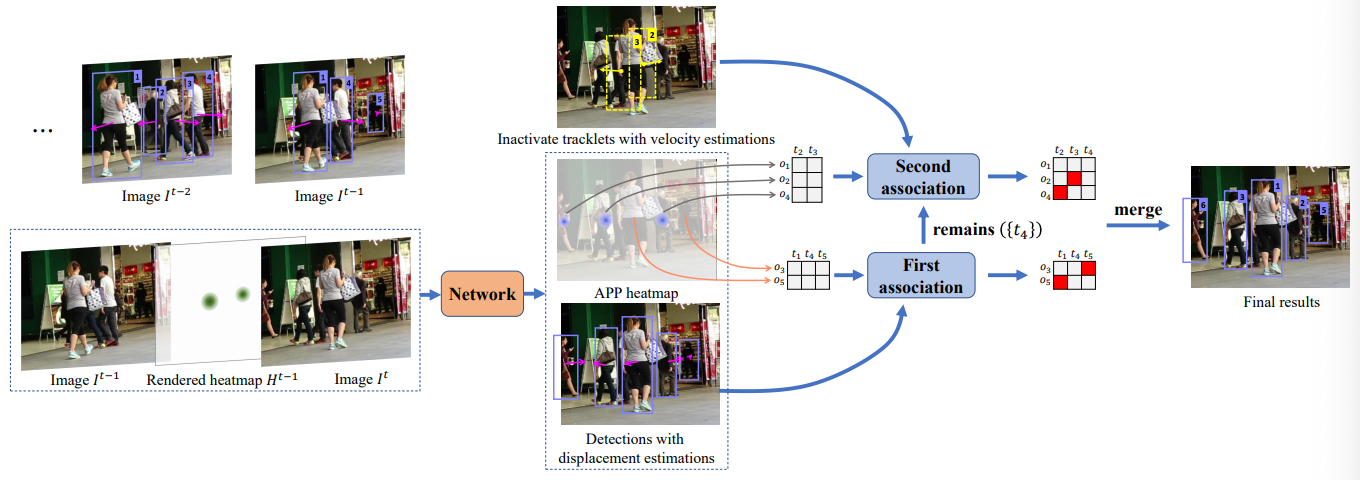
Tao Zhou, Wenhan Luo, Zhiguo Shi, Jiming Chen, Qi Ye,
The 30th ACM International Conference on Multimedia (ACM MM), 2022.
[PDF] [Project Page]

Kaihao Zhang, Dongxu Li, Wenhan Luo, Jingyu Liu, Jiankang Deng, Wei Liu, Stefanos Zafeiriou,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), vol. 45, pp. 3968-3978, 2023.
[PDF] [Github] [Project Page]

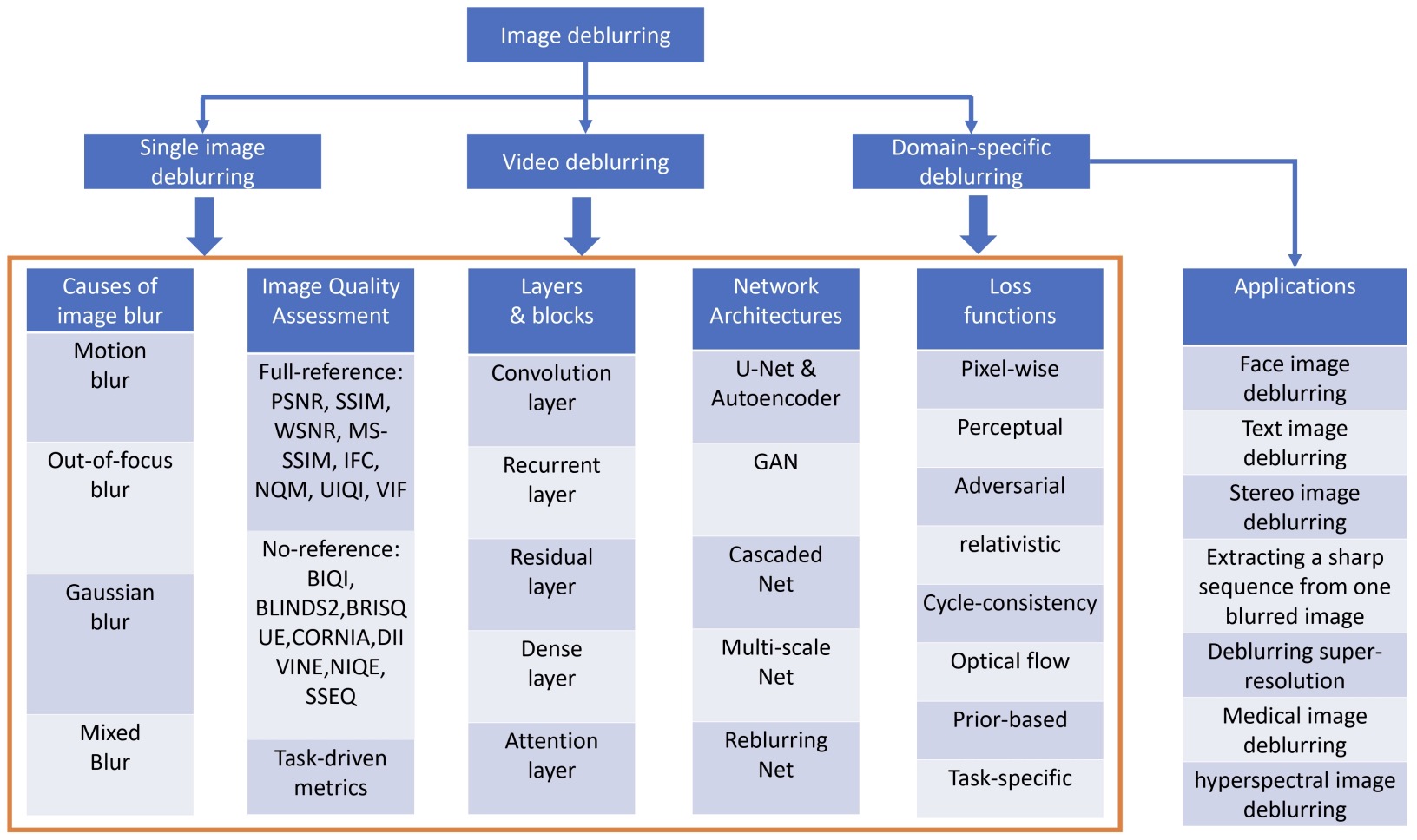
Kaihao Zhang, Wenqi Ren, Wenhan Luo, Wei-Sheng Lai, Bjorn Stenger, Ming-Hsuan Yang, Hongdong Li,
International Journal of Computer Vision (IJCV), vol. 130, pp. 2103-2130, 2022. (Highly Cited Paper)
[PDF]
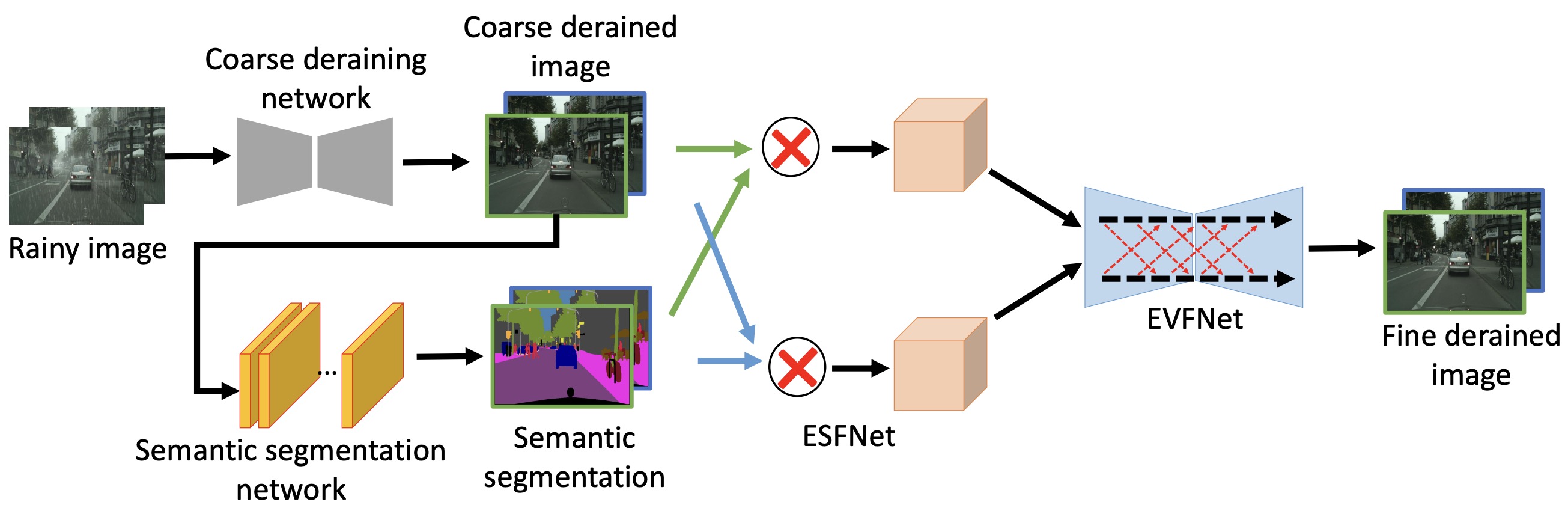
Kaihao Zhang, Wenhan Luo, Yanjiang Yu, Wenqi Ren, Fang Zhao, Changsheng Li, Lin Ma, Wei Liu, Hongdong Li,
International Journal of Computer Vision (IJCV), vol. 130, pp. 1754-1769, 2022.
[PDF] [Github]

Yizhi Wang, Guo Pu, Wenhan Luo, Yexin Wang, Pengfei Xiong, Hongwen Kang, Zhouhui Lian,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2022.
[PDF] [Dataset/Code]

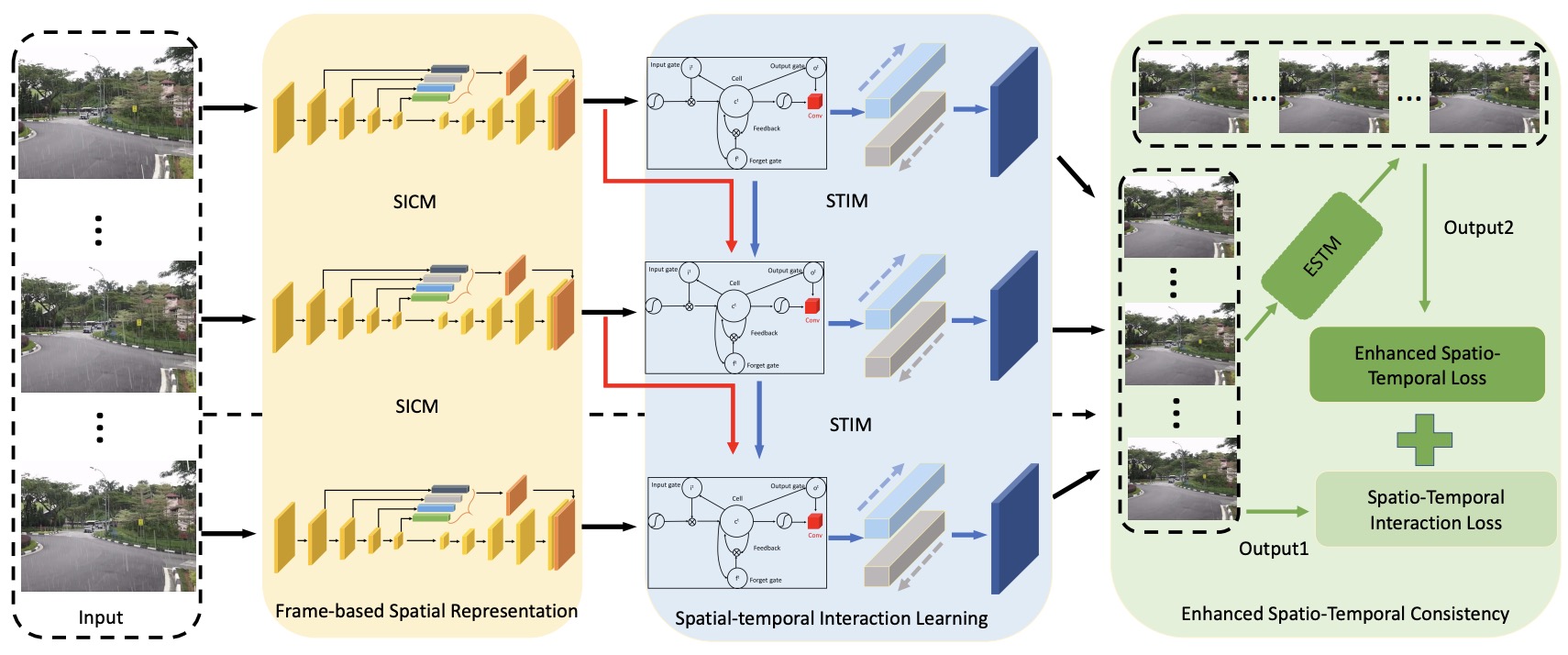
Kaihao Zhang, Dongxu Li, Wenhan Luo, Wenqi Ren, Wei Liu,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), vol. 45, pp. 1287-1293, 2023. (Highly Cited Paper)
[arXiv] [Dataset/Code]

Kaihao Zhang, Dongxu Li, Wenhan Luo, Wenqi Ren,
IEEE Trans. on Image Processing (TIP), vol. 30, pp. 7608-7619, 2021.
[PDF]

Kaihao Zhang, Rongqing Li, Yanjiang Yu, Wenhan Luo, Changsheng Li,
IEEE Trans. on Image Processing (TIP), vol. 30, pp. 7419-7431, 2021. (Highly Cited Paper)
[PDF] [Dataset/Code]

Kaihao Zhang, Dongxu Li, Wenhan Luo, Wenqi Ren, Bjorn Stenger, Wei Liu, Hongdong Li, Ming-Hsuan Yang,
Proc. of International Conference on Computer Vision (ICCV), 2021.
[PDF] [Dataset]
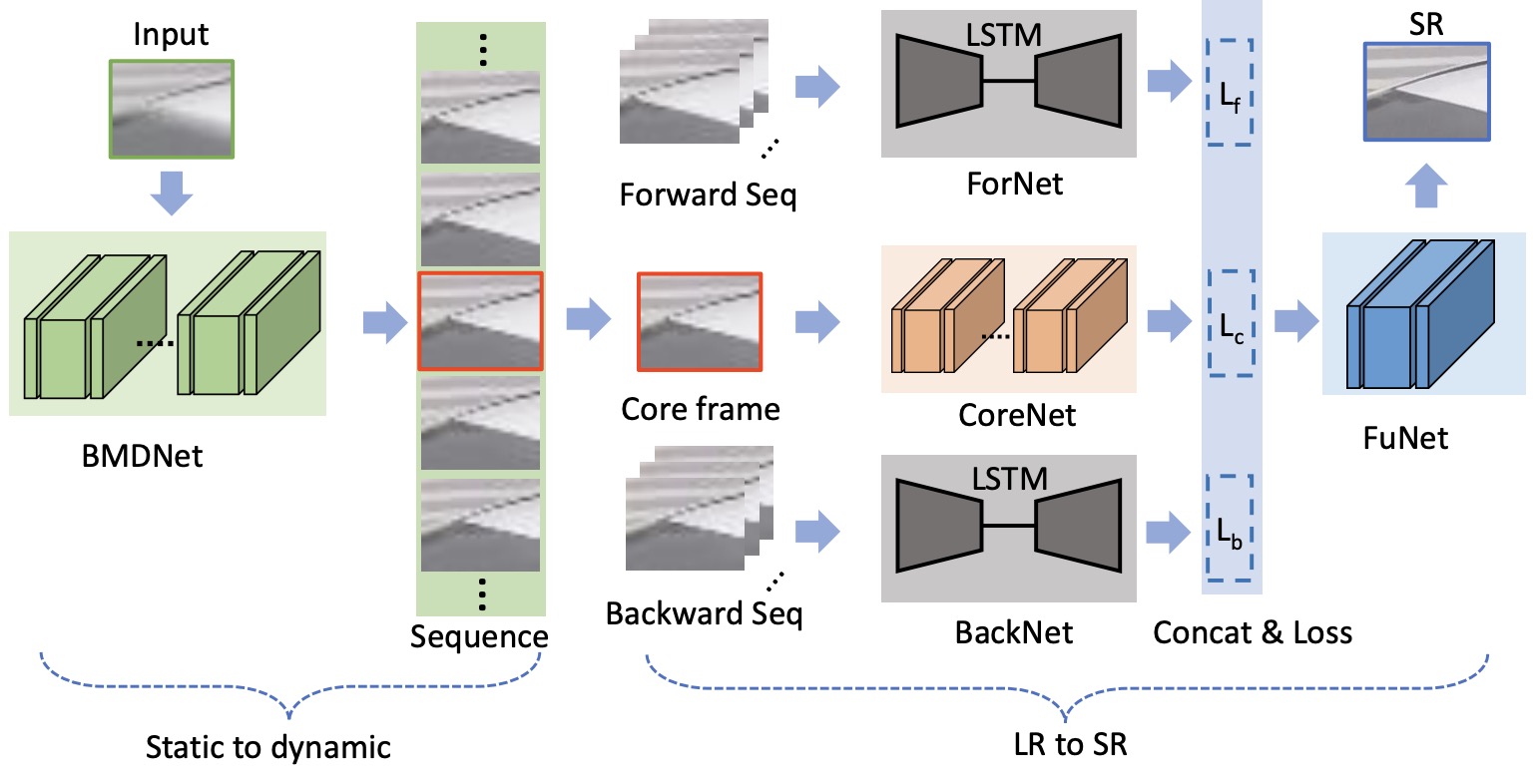
Wenjia Niu, Kaihao Zhang, Wenhan Luo, Yiran Zhong,
IEEE Trans. on Image Processing (TIP), vol. 30, pp. 7101-7111, 2021.
[PDF]
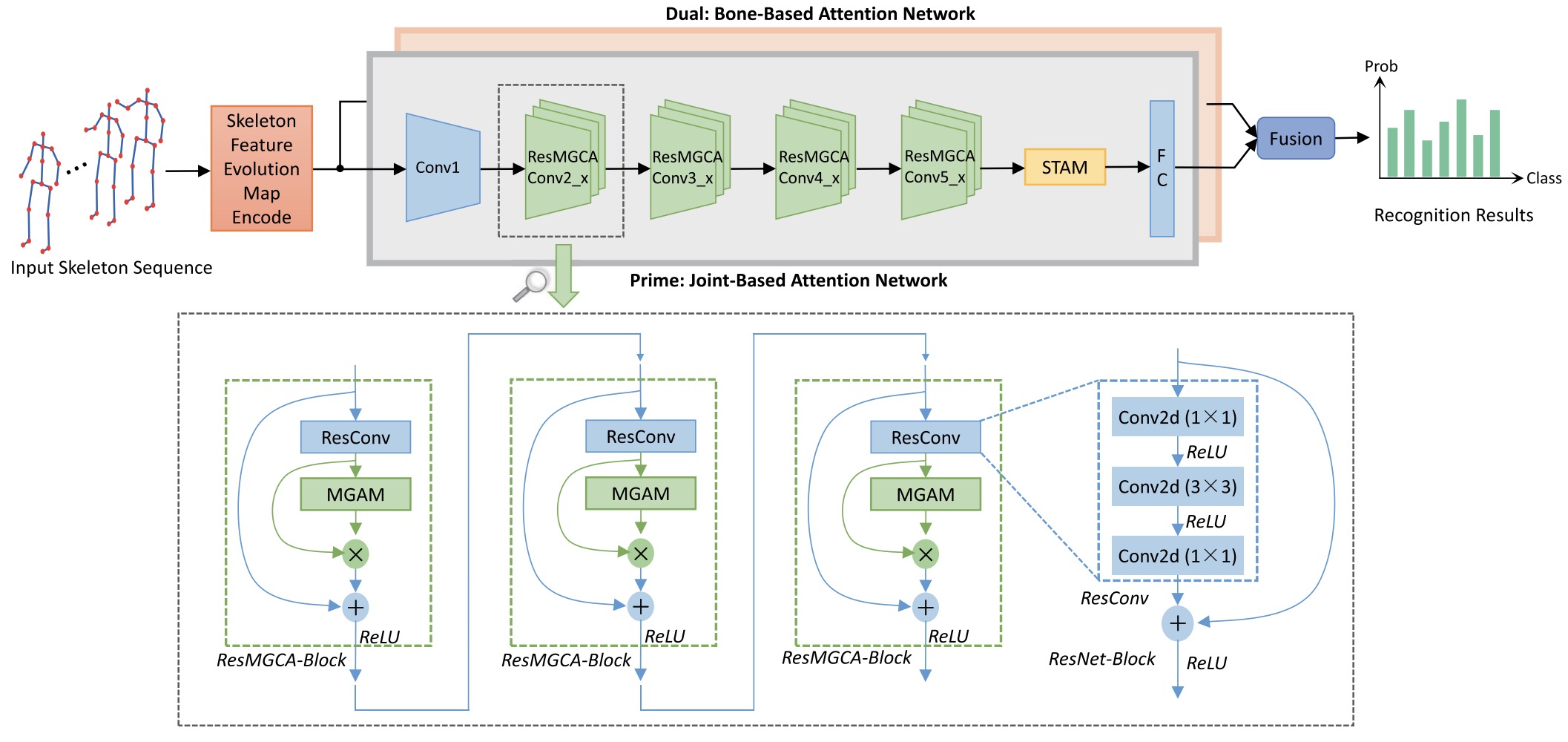
Rongjie Xia, Yanshan Li, Wenhan Luo,
IEEE Transactions on Multimedia (TMM), vol. 24, pp. 2648-2661, 2022.
[PDF]

Fangwei Zhong, Peng Sun, Wenhan Luo, Tingyun Yan, Yizhou Wang,
International Conference on Machine Learning (ICML), 2021.
[PDF] [Code]


Xiaoqin Zhang, Runhua Jiang, Tao Wang, Wenhan Luo,
IEEE Trans. on Image Processing (TIP), vol. 30, pp. 5211-5222, 2021.
[PDF]

Wen Liu, Zhixin Piao, Zhi Tu, Wenhan Luo, Lin Ma, Shenghua Gao,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), vol. 44, pp. 5114-5132, 2022.
[PDF] [Code]

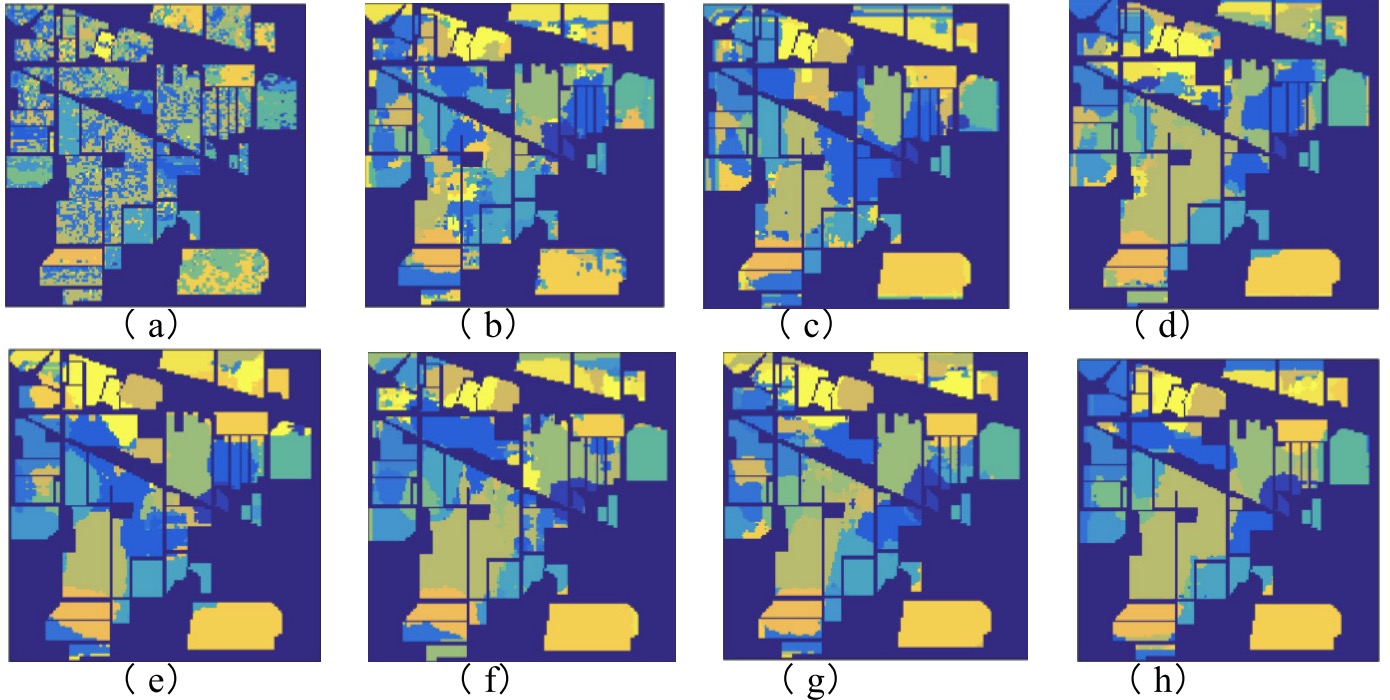
Yanshan Li, Haojin Tang, Weixin Xie, Wenhan Luo,
IEEE Trans. on Geoscience and Remote Sensing, vol. 60, pp. 1-13, 2022.
[PDF]
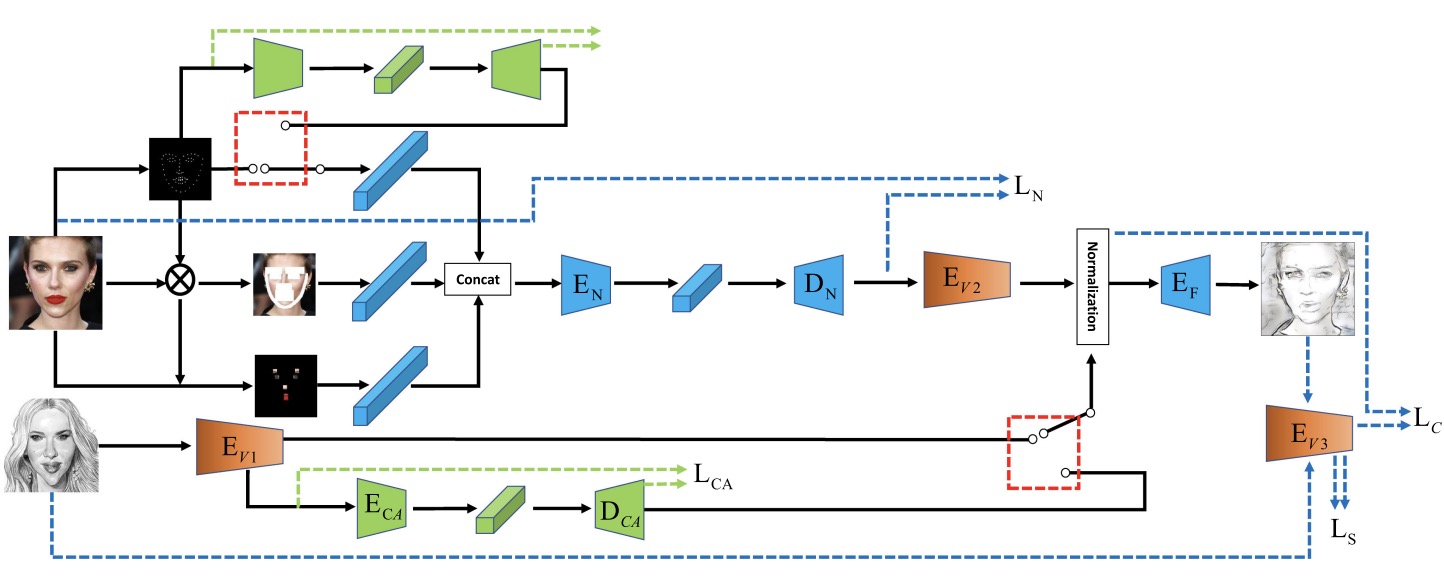
Kaihao Zhang, Wenhan Luo, Lin Ma, Wenqi Ren, Hongdong Li,
IEEE Transactions on Multimedia (TMM), vol. 24, pp. 1378-1388, 2022.
[PDF]
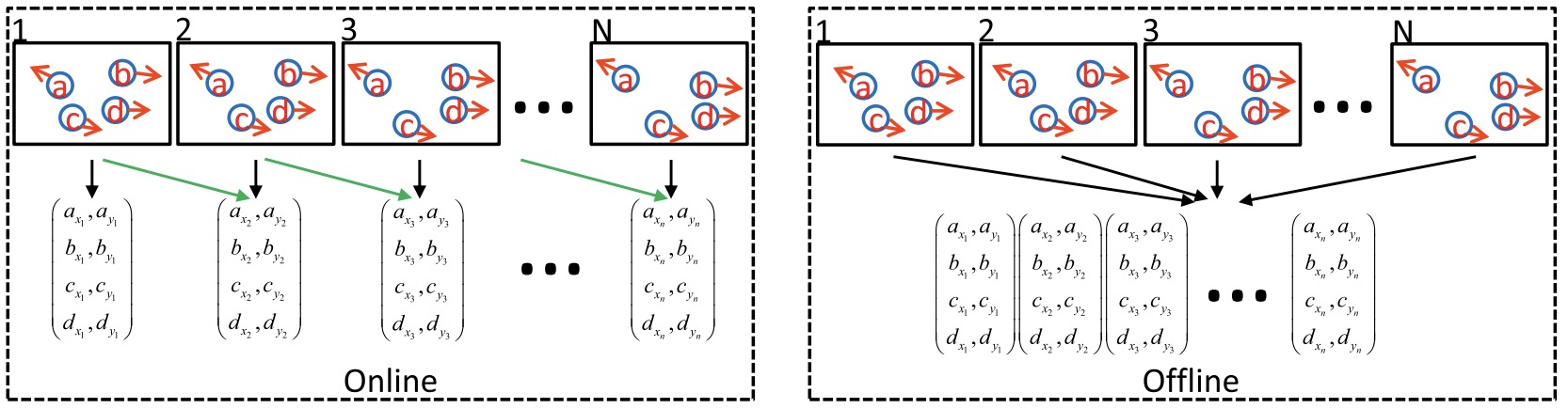
Wenhan Luo, Junliang Xing, Anton Milan, Xiaoqin Zhang, Wei Liu, Tae-Kyun. Kim,
Artificial Intelligence, vol. 293, pp. 103448, 2021. (Highly Cited Paper)
[PDF]

Xiaoqin Zhang, Tao Wang, Wenhan Luo, Pengcheng Huang,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), vol. 31, pp. 4162-4173, 2021. (Highly Cited Paper)
[PDF]
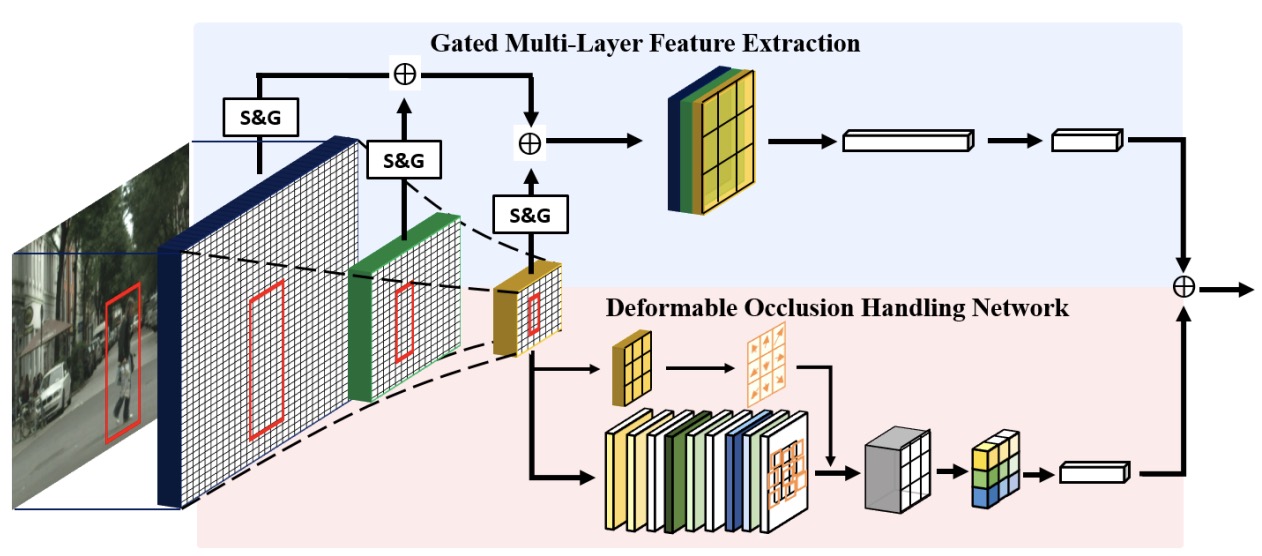
Tianrui Liu, Wenhan Luo, Lin Ma, Junjie Huang, Tania Stathaki, Tianhong Dai,
IEEE Trans. on Image Processing (TIP), vol. 30, pp. 754-766, 2021.
[PDF]
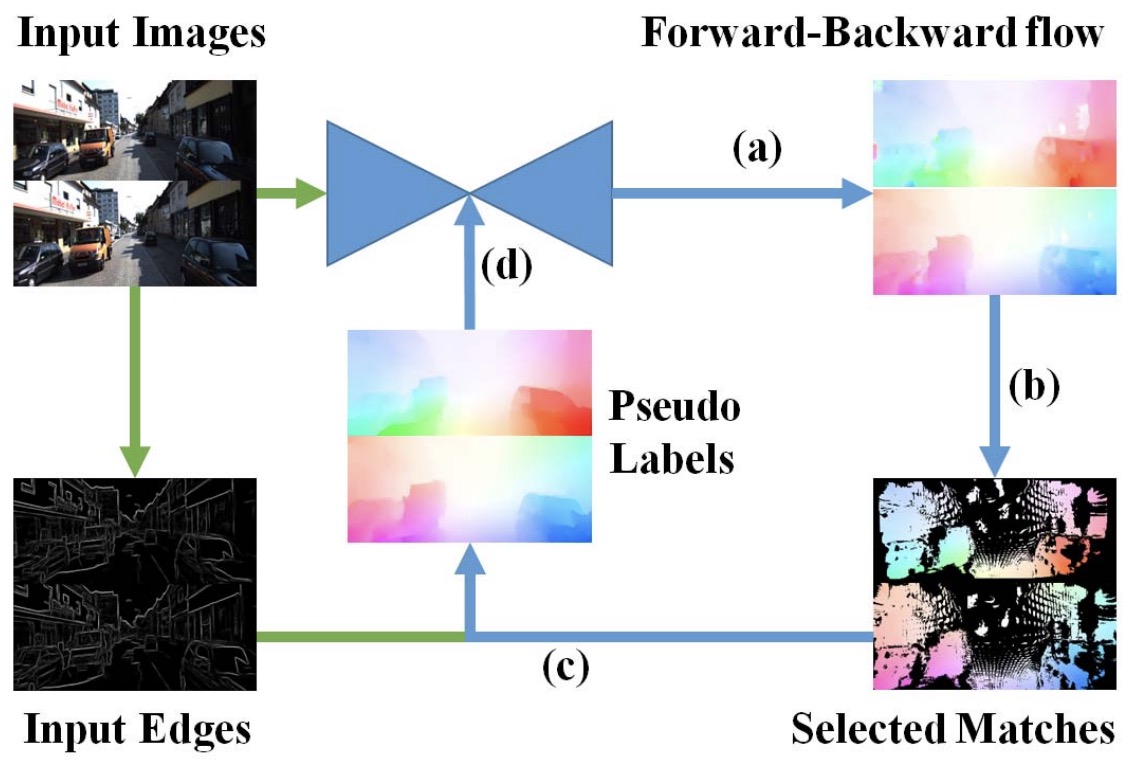
Zhe Ren, Wenhan Luo, Junchi Yan, Xiaokang Yang, Alan Yuille, Hongyuan Zha,
IEEE Trans. on Image Processing (TIP), vol. 29, pp. 9113-9124, 2020.
[PDF]

Kaihao Zhang, Wenhan Luo, Bjorn Stenger, Wenqi Ren, Lin Ma, Hongdong Li
The 28th ACM International Conference on Multimedia (ACM MM), 2020. (Oral)
[PDF]
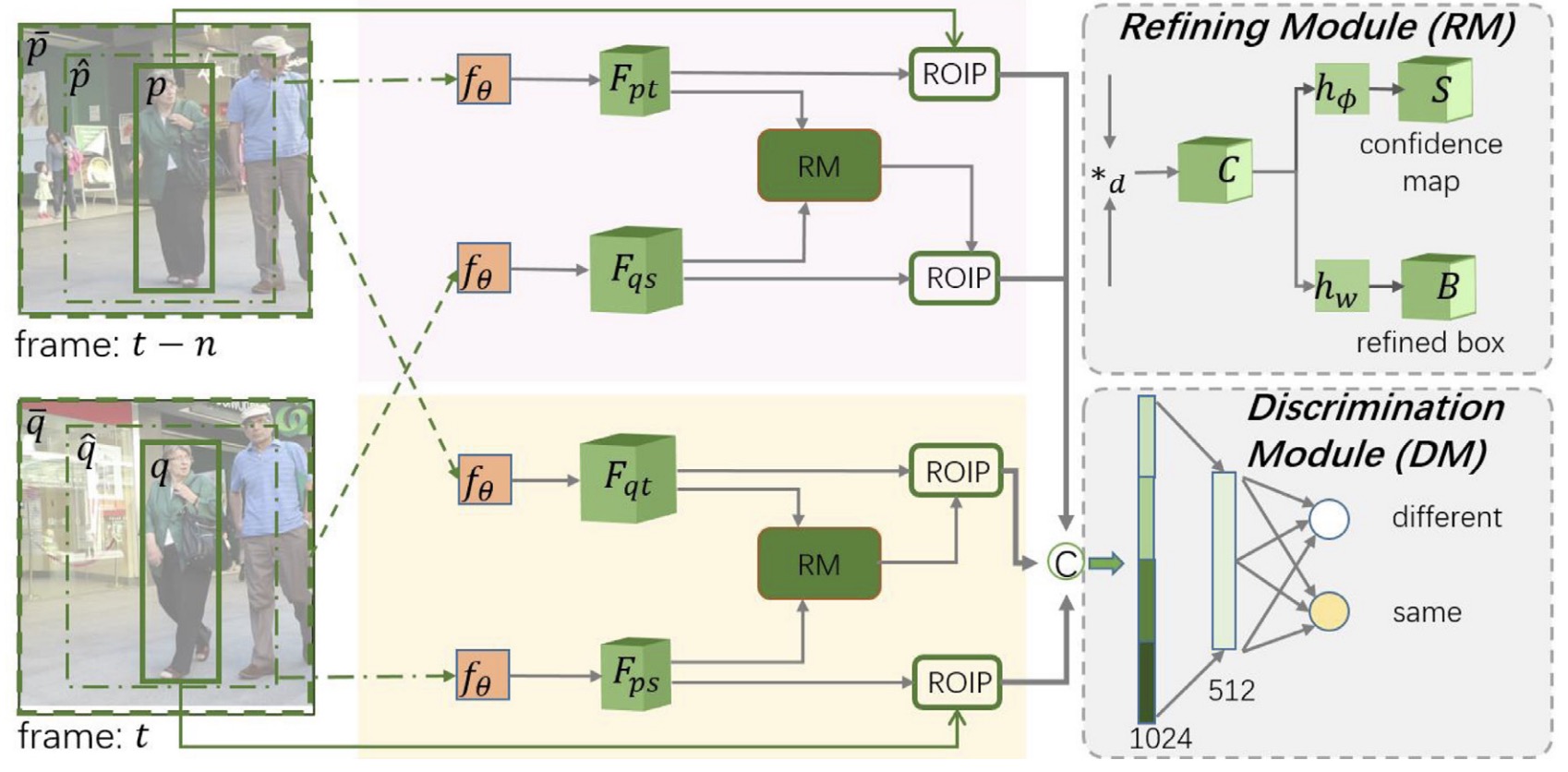
Zongwei Zhou, Wenhan Luo, Qiang Wang, Junliang Xing, Weiming Hu,
Pattern Recognition, vol. 107, pp. 107512, 2020.
[PDF]

Kaihao Zhang, Wenhan Luo, Wenqi Ren, Jingwen Wang, Fang Zhao, Lin Ma, Hongdong Li,
European Conference on Computer Vision (ECCV), UK, 2020.
[PDF] [Dataset (zzkd)] [Code (ehl2)] [Results (yb4y)] [Github]

Kaihao Zhang, Wenhan Luo, Yiran Zhong, Lin Ma, Bjorn Stenger, Wei Liu, Hongdong Li,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2020. (Oral)
[PDF] [Dataset/Code]

Wei Xiong, Yutong He, Yixuan Zhang, Wenhan Luo, Lin Ma, Jiebo Luo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2020.
[PDF] [Project Page]

Tao Wang, Xiaoqin Zhang, Runhua Jiang, Li Zhao, Huiling Chen, Wenhan Luo,
Computer Vision and Image Understanding (CVIU), vol. 203, pp. 103135, 2021.
[PDF]
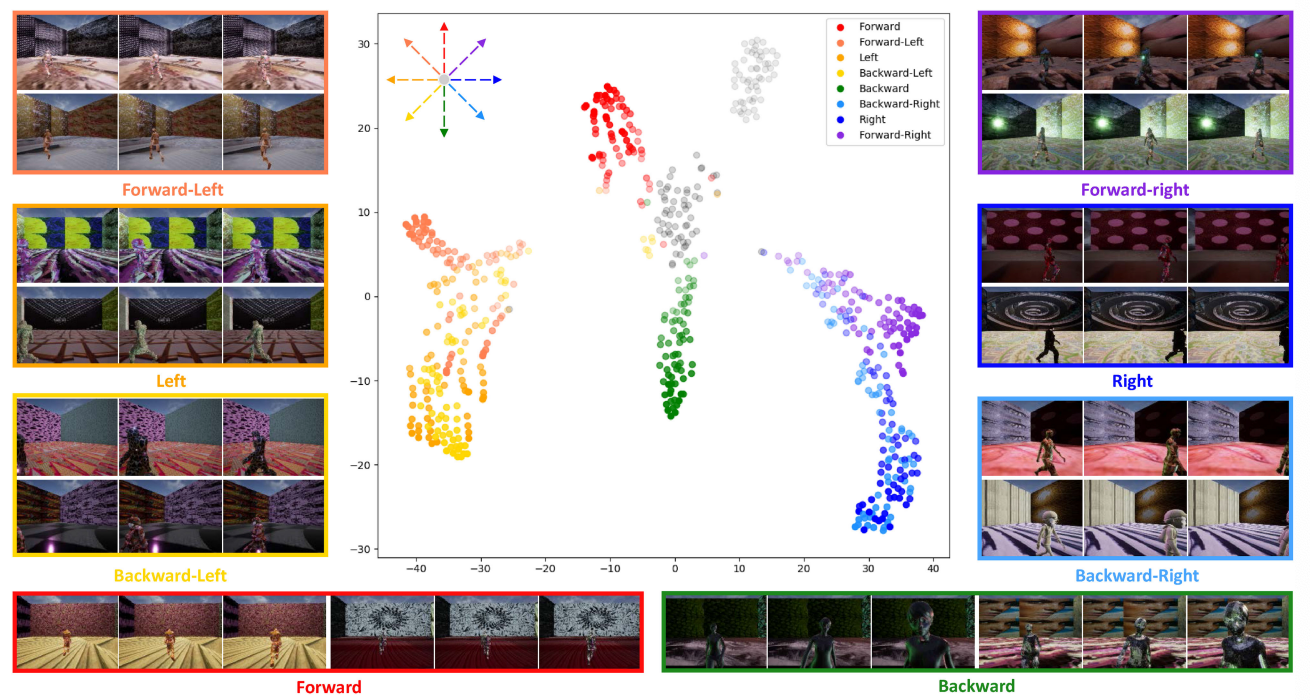
Fangwei Zhong, Peng Sun, Wenhan Luo, Tingyun Yan, Yizhou Wang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), vol. 43, pp. 1467-1482, 2021.
[PDF] [Code] [Demo] [Dataset]

Wen Liu, Zhixin Piao, Jie Min, Wenhan Luo, Lin Ma, Shenghua Gao,
Proc. of International Conference on Computer Vision (ICCV), Korea, 2019.
[PDF] [Project Page] [Code] [Dataset]

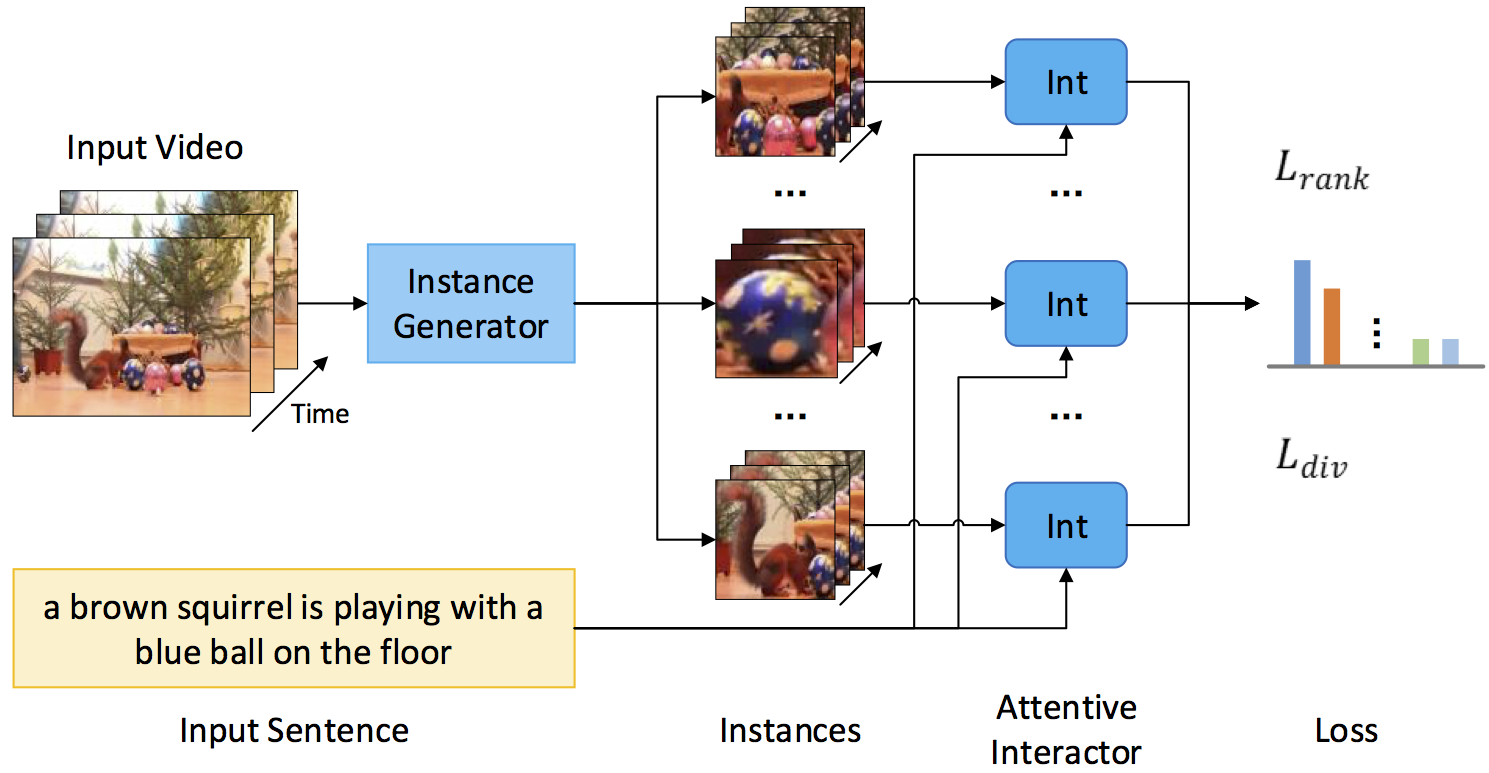
Zhenfang Chen, Lin Ma, Wenhan Luo, Kwan-Yee K Wong,
The 57th Annual Meeting of the Association for Computational Linguistics (ACL), Italy, 2019. (Oral)
[PDF] [Code]

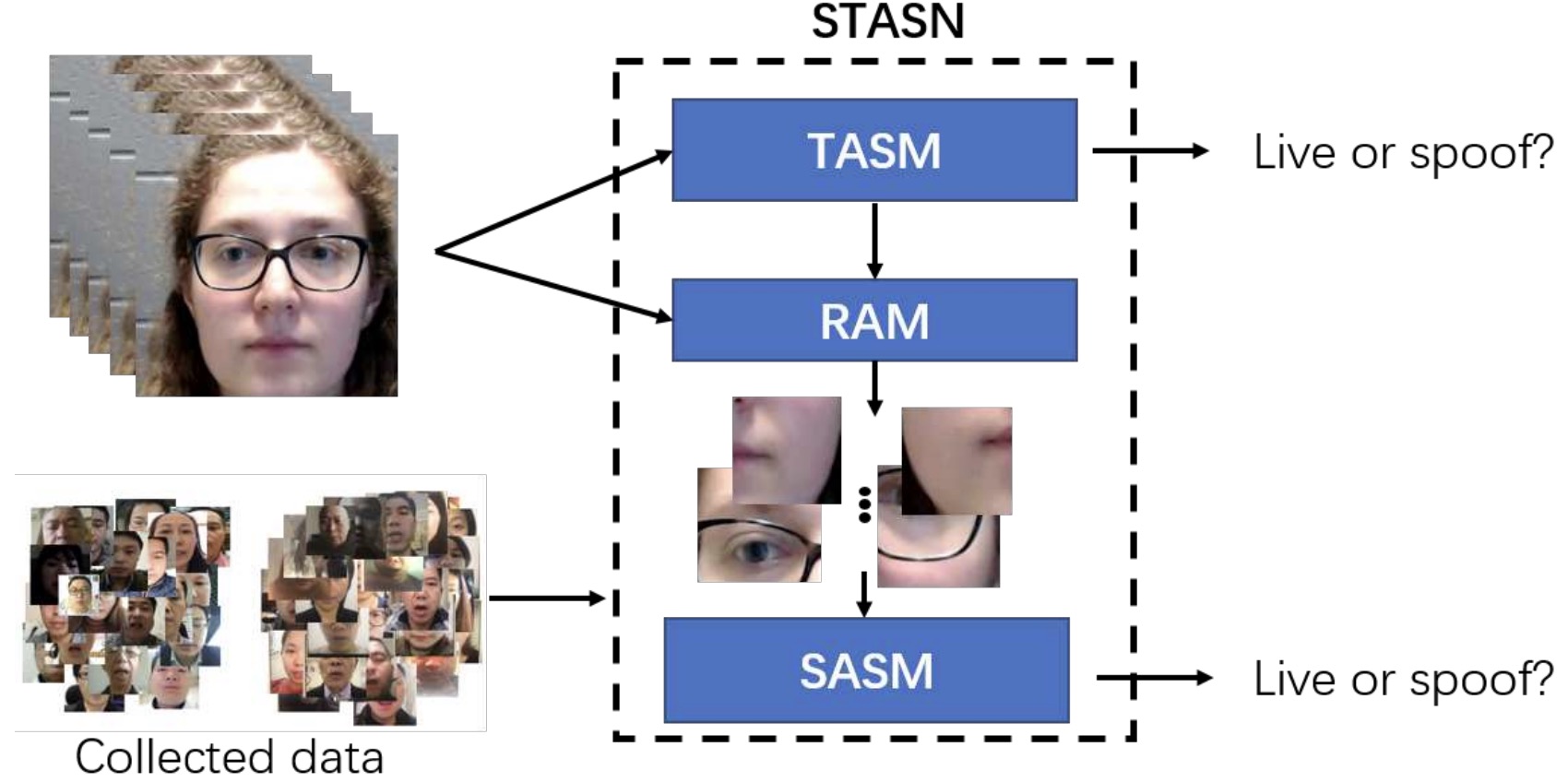
Xiao Yang*, Wenhan Luo*, Linchao Bao, Yuan Gao, Dihong Gong, Shibao Zheng, Zhifeng Li, Wei Liu,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2019.
[PDF]
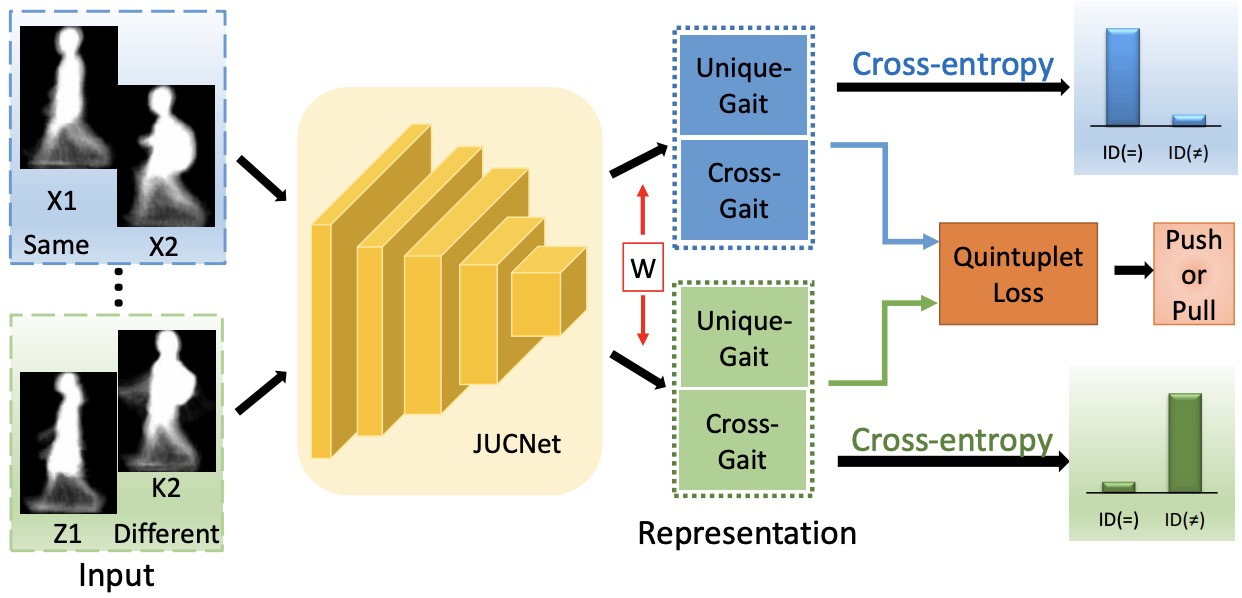
Kaihao Zhang, Wenhan Luo, Lin Ma, Wei Liu, Hongdong Li,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2019. (Oral)
[PDF]
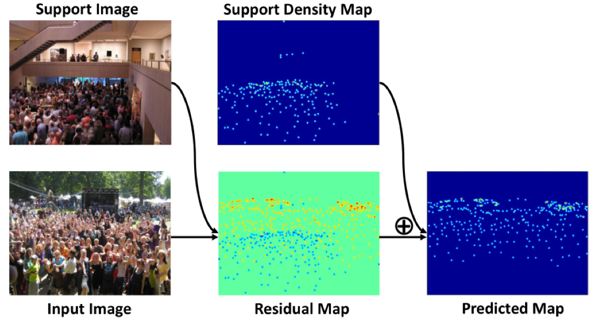
Jia Wan, Wenhan Luo, Baoyuan Wu, Antoni Chan, Wei Liu,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2019.
[PDF] [Project Page] [Code]
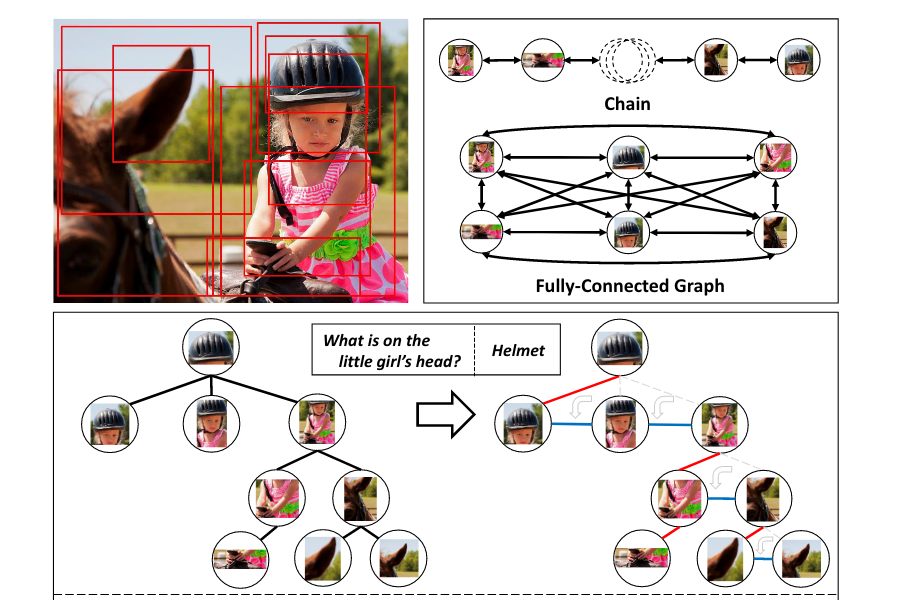
Kaihua Tang, Hanwang Zhang, Baoyuan Wu, Wenhan Luo, Wei Liu,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2019. (Oral & Best Paper Finalist)
[arXiv] [Code]

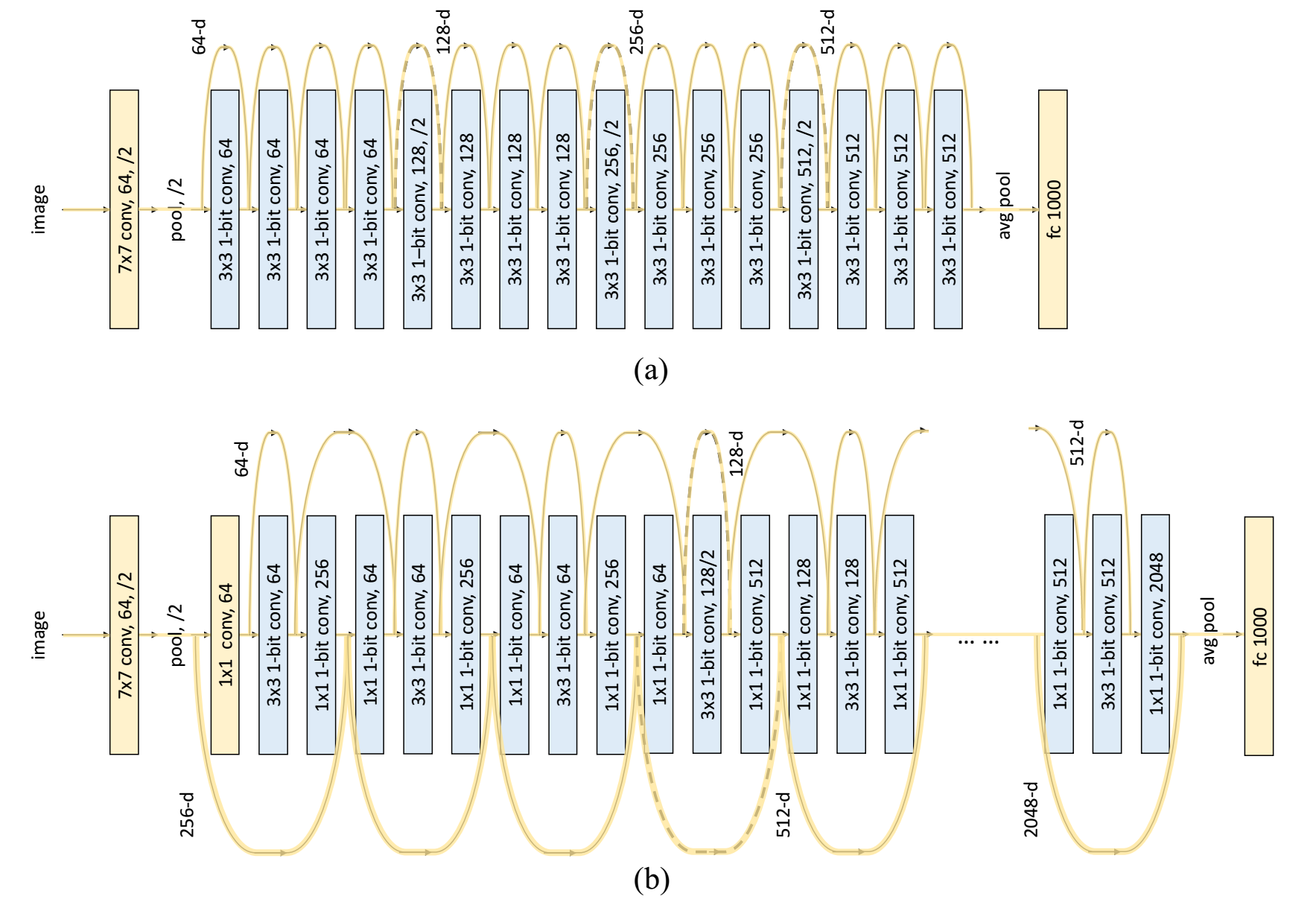
Zechun Liu, Wenhan Luo, Baoyuan Wu, Xin Yang, Wei Liu, Kwang-Ting Cheng,
International Journal of Computer Vision (IJCV), vol. 128, pp. 202-219, 2020.
[PDF] [arXiv] [Code]

Fangwei Zhong, Peng Sun, Wenhan Luo, Tingyun Yan, Yizhou Wang,
International Conference on Learning Representations (ICLR), New Orleans, USA, 2019.
[OpenReview Link] [Code] [Dataset]
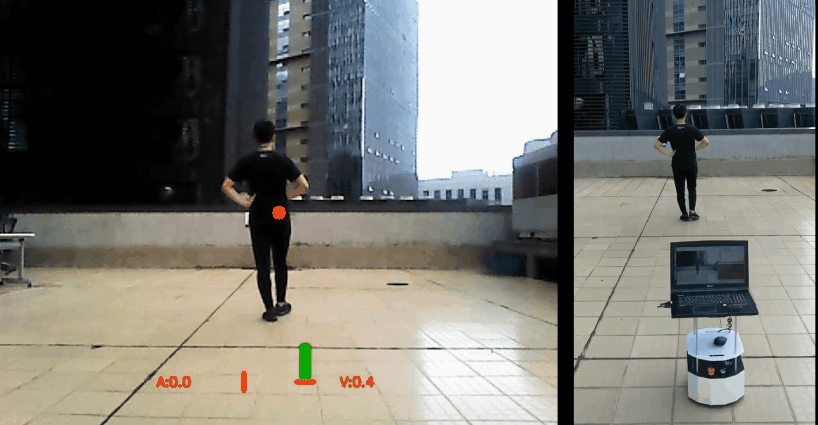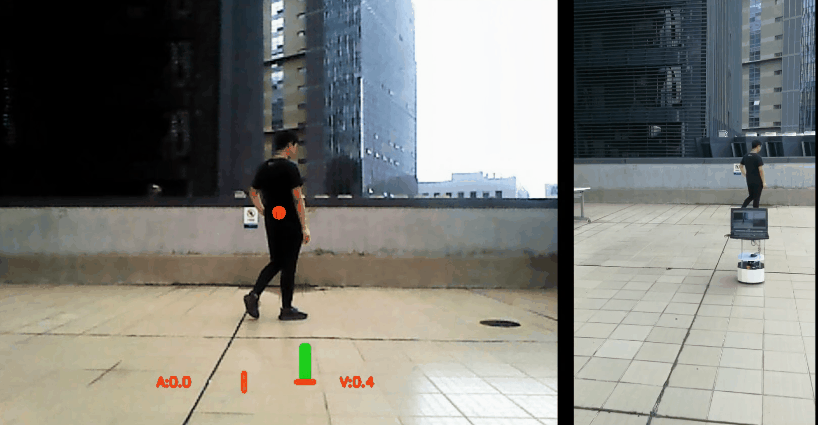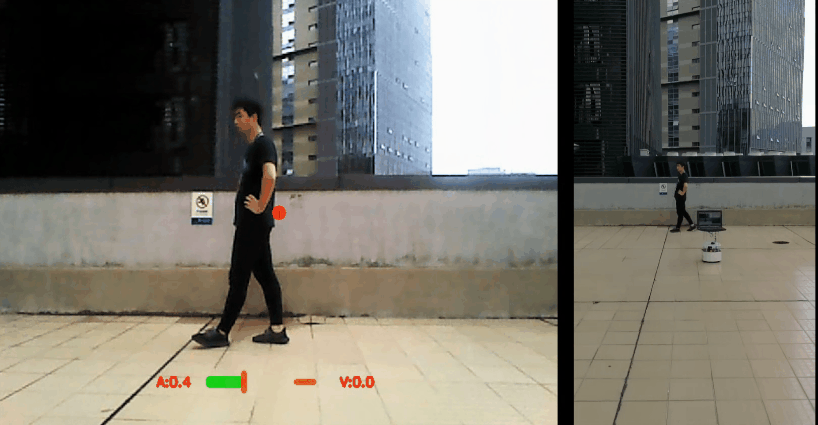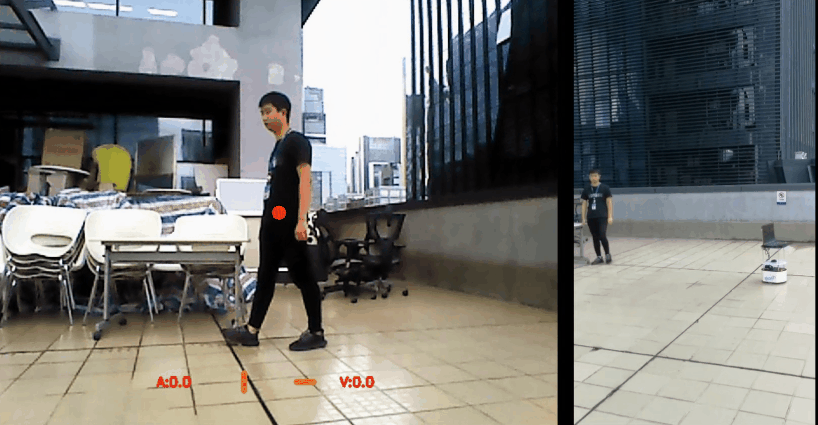
Wenhan Luo*, Peng Sun*, Fangwei Zhong*, Wei Liu, Tong Zhang, Yizhou Wang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), vol. 42, pp. 1317-1332, 2020.
[arXiv] [Project Page] [Code] [Environment]

Kaihao Zhang, Wenhan Luo, Lin Ma, Hongdong Li,
Proc. of the Association for the Advancement of Artificial Intelligence (AAAI), Hawaii, USA, 2019. (Spotlight)
[PDF]

Kaihao Zhang, Wenhan Luo, Yiran Zhong, Lin Ma, Wei Liu, Hongdong Li,
IEEE Trans. on Image Processing (TIP), vol. 28, no. 1, pp. 291-301, 2019.
[arXiv] [Code]

Wenhan Luo, Bjorn Stenger, Xiaowei Zhao, Tae-Kyun Kim,
IEEE Trans. on Image Processing (TIP), vol. 28, no. 1, pp. 240-252, 2019.
[PDF]
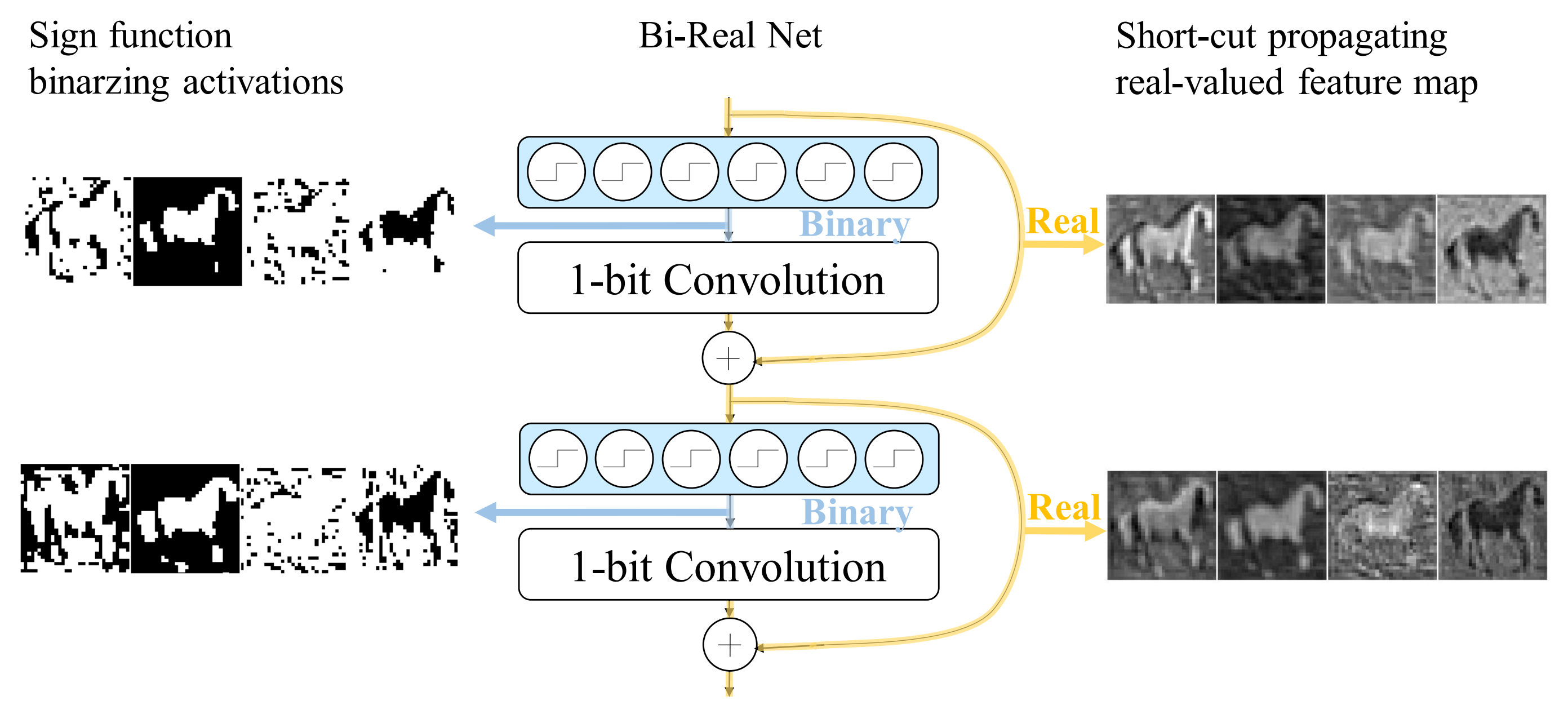
Zechun Liu, Baoyuan Wu, Wenhan Luo, Xin Yang, Wei Liu, Kwang-Ting Cheng,
European Conference on Computer Vision (ECCV), Germany, 2018.
[PDF] [Code]
Wenhan Luo*, Peng Sun*, Fangwei Zhong, Wei Liu, Tong Zhang, Yizhou Wang,
International Conference on Machine Learning (ICML), Sweden, 2018.
[PDF] [Project Page] [Code] [Demo]
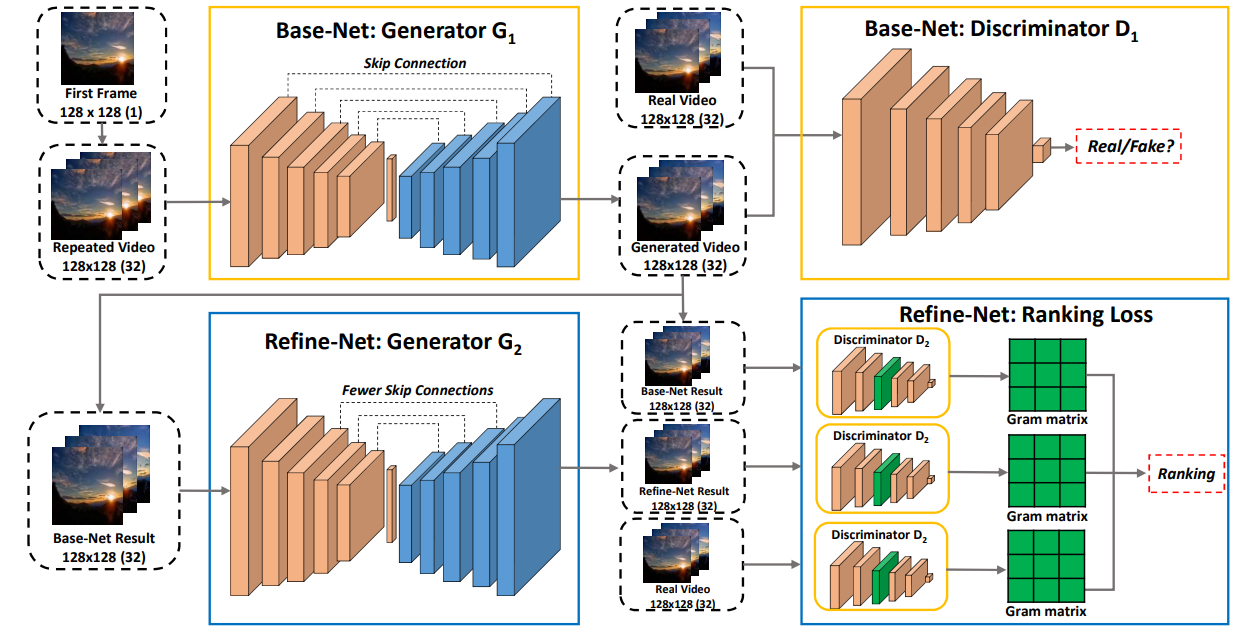
Wei Xiong, Wenhan Luo, Lin Ma, Wei Liu, Jiebo Luo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2018.
[arXiv] [Project Page] [Code] [Dataset]


Haozhi Huang, Hao Wang, Wenhan Luo, Lin Ma, Wenhao Jiang, Xiaolong Zhu, Zhifeng Li, Wei Liu,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), USA, 2017.
[PDF]
Wenhan Luo, Bjorn Stenger, Xiaowei Zhao, Tae-Kyun Kim,
Proc. of the Association for the Advancement of Artificial Intelligence (AAAI), Austin, Texas, USA, 2015. (Oral)
[PDF]
Wenhan Luo, Tae-Kyun Kim, Bjorn Stenger, Xiaowei Zhao, Roberto Cipolla,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Columbus, Ohio, USA, 2014.
[PDF]

Xiaowei Zhao, Tae-Kyun Kim, Wenhan Luo,
Proc. of IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Columbus, Ohio, USA, 2014.
[PDF]